什么是数据库系统
- DBMS是指一个能为用户提供信息服务的系统,它实现了有组织的,动态的储存大量相关数据的功能,提供了数据处理和信息资源共享的便利手段
关系型数据库 (RDBMS)
- 使用了关系模型的数据库系统
- 关系模型中,数据是分类存放的,数据之间可以有联系
什么是NoSQL数据库
- NoSQL数据库指的是数据分类存放,但是数据之间没有关联关系的数据库系统
MySQL配置文件
- MySQL默认的root用户拥有所有权限,并且只能通过localhost登录,所以我们可以新建一个用户
- 我们可以使用Terminal指令 mysql -u root -p 来登录MySQL数据库
- 我们可以使用第三方的MySQL图形界面登录管理MySQL database
- sequel pro
- DataGrip
- NaviCat
- 我们可以设置各种MySQL的配置,例如字符集,端口号,目录地址等等
SQL语言分类
- DML - 对数据进行操作,层删改查
- DCL - 数据库控制语言,控制用户,权限,事务
- DDL - definition,对逻辑库,数据表,视图,索引进行操作
SQL语句注意事项
- SQL语句不区分大小写
- 必须以分号结尾
- 语句中的空白和换行没有限制
注释
# this is single line comment/* this is multi line comments */
创建逻辑库
- CREATE DATABASE database_name;
- SHOW DATABASES;
- DROP database_name;
创建数据表
1 | CREATE TABLE student ( |
数据表的其他操作
- SHOW tables;
- DESC student;
- SHOW CREATE TABLE student;
- DROP TABLE student;
不精确的浮点数
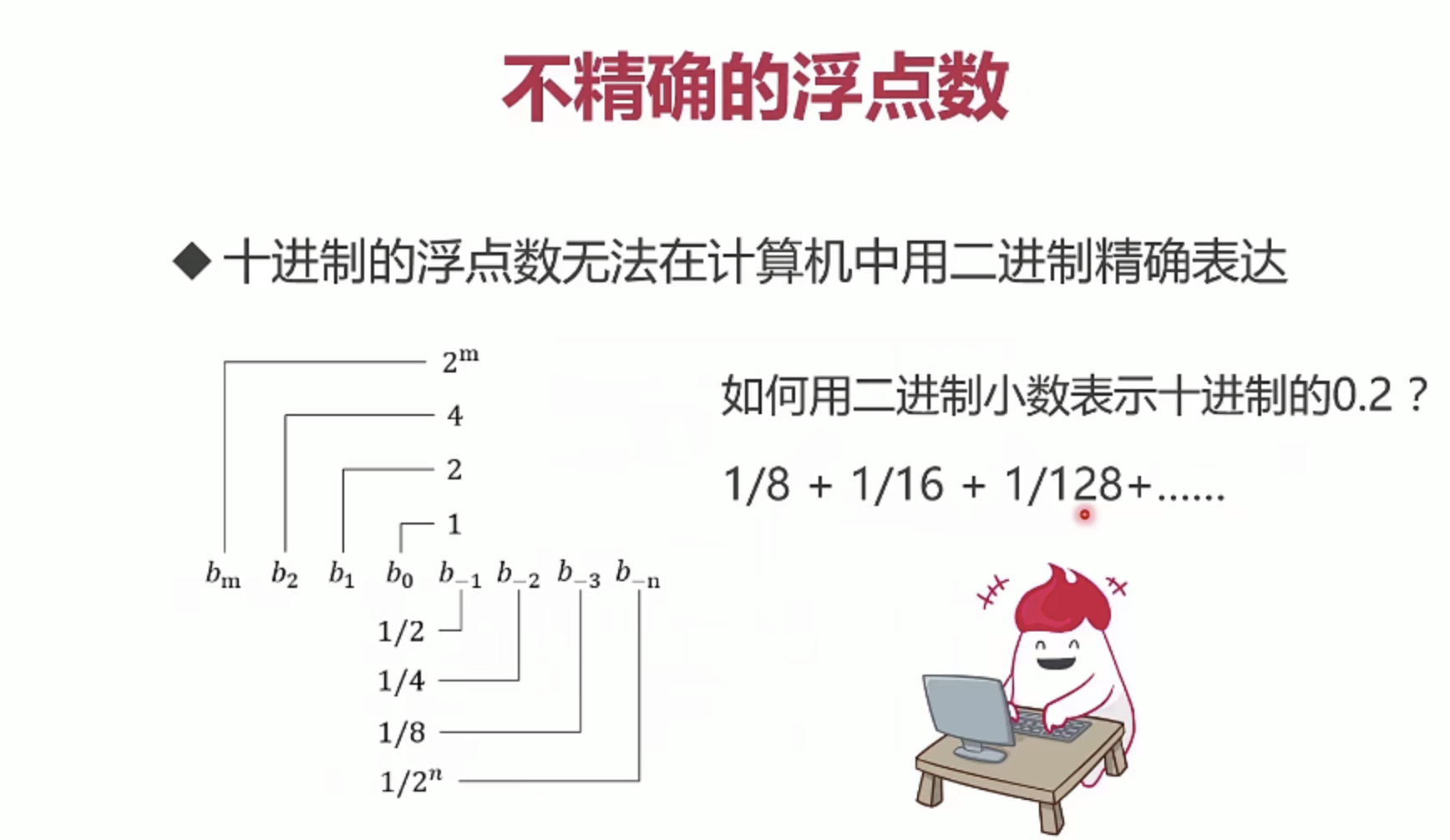
- 所以在保存重要数字的时候要选用DECIMAL类型,它会将数字以字符串的形式保存,不会丢失精度
修改表结构
- 添加新字段
1 | ALTER TABLE student |
- 修改字段
1 | ALTER TABLE student |
- 修改字段名称
1 | ALTER TABLE student |
- 删除字段
1 | ALTER TABLE student |
字段约束
数据库的范式
- 构造数据库必须遵循一定的规则,这种规则就是范式
- 目前关系数据库有6种范式,一般情况下,只满足第三范式即可
第一范式:原子性
- 第一范式是数据库的基本要求,不满足这一点就不是关系型数据库
- 数据表的每一列都是不可分割的基本数据项,同一列中不能有多个值,也不能存在重复的属性
第二范式:唯一性
- 数据表中的每条记录必须是唯一的,为了实现区分,通常要为表加上一个列用来储存唯一标识,这个唯一属性列被称作主键列
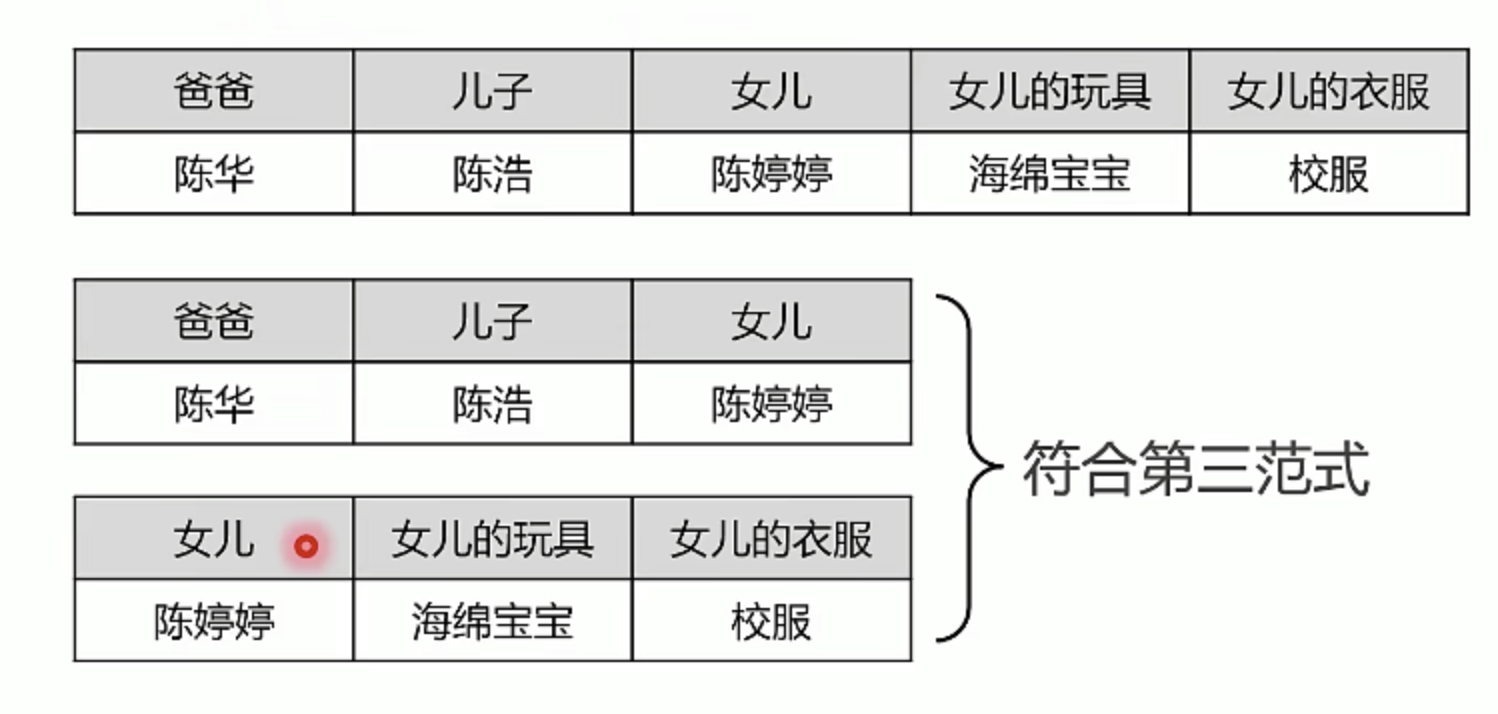
第三范式:关联性
-
每列都与主键有直接关系,不存在依赖传递
-
下图中爸爸是主键,但是女儿的玩具和女儿的衣服并不依赖与主键,而是依赖于女儿,所以不满足第三范式
-
依照第三范式,数据可以拆分保存到不同的数据表,彼此保持关联
MySQL中的字段约束
- 主键约束 - PRIMARY KEY - 字段值唯一,且不能为NULL
- 建议主键一定要使用数字类型,因为数字的检索速度会非常快
- 如果主键是数字类型,还可以设置自动增长
- 非空约束 - NOT NULL - 字段值不能为NULL
- 非空字段可以有默认值
name VARCHAR(20) NOT NULL DEFAULT "default name"
- 唯一约束 - UNIQUE - 字段值唯一,且可以为NULL
- 外键约束 - FOREIGN KEY - 保持关联数据的逻辑性
外键约束的闭环问题
- 如果形成外键闭环,我们将无法删除任何一张表的记录
索引
数据排序的好处
- 一旦数据排序之后,查找的速度就会翻倍
如何创建索引
- 当数据排序后,MySQL后台会对索引对象创建二叉树,使用二分查找提升速度
1 | create table t_message ( |
如何添加与删除索引
1 | drop index idx_type on t_message; |
索引的使用原则
- 数据量很大,而且经常被查询到的数据表可以设置索引
- 索引只添加在经常被用作检索条件的字段上面
- 不要在大字段上创建索引
数据操作语言
记录查询
- 最基本的查询语言是由select和from关键字组成的
- select语句屏蔽了物理层的操作,用户不必关心数据的真实存储,交由数据库高效的查找数据
使用列别名
- 通常情况下,select子句中使用了表达式,那么这列的名字就默认为表达式,因此需要一种对列名重命名的机制
数据分页
- 如果记录很多,我们可以使用LIMIT关键字来限定结果数量
Select ... from ... limit startPosition, offset- 如果LIMIT子句只有一个参数,他表示的是offset,起始值默认为0
排序
- 如果没有设置,查询语句不会对结果集进行排序,如果想让结果按照某种顺序排列,就必须使用ORDER BY子句
- ASC代表升序,DESC代表降序
- 如果排序列是数字类型,数据库就按照数字大小排列,如果是日期类型,就按照日期排序,如果是字符串就按照字符集序号排序
去除重复记录
- DISTINCT
- DISTINCT关键字只能使用一次,并且放在最前面
条件查询
- WHERE
聚合函数
- 求和,最大值,最小值,平均值,COUNT。。。
数据分组
- GROUP BY
- 通过一定的规则讲一个数据集划分成若干个小的区域,然后针对每个小区域分别进行数据汇总处理
- 数据库支持多列分组条件,执行的时候逐级分组
- WITH ROLLUP 对分组结果再次做汇总计算
GROUP_CONCAT函数
-
把分组查询中的某个字段拼接成一个字符串
-
查询每个部门工资大于2000 的
1 | select deptno, GROUP_CONCAT(ename), COUNT(*) |
HAVING子句
- 查询每个部门中,1982年以后入职的员工超过2个人的部门编号
1 | select deptno |
表连接
1 | select e.empno, e.ename, d.dname |
表连接的分类
- 内连接,外连接
- 内连接是结果集中只保留符合连接条件的记录
- 外连接是不管符不符合连接条件,记录都要保留在结果集中
内连接
- 用于查询多张关系表符合条件的记录
- INNER JOIN
- 相同的数据表也可以做表连接
外连接
-
LEFT JOIN
-
RIGHT JOIN
-
左外连接就是保留左表所有的记录,与右表做链接,如果右表有符合条件的记录就与左表链接,如果没有,就用NULL与左表链接
-
右外连接也是如此
-
UNION关键字可以将多个查询语句的结果集进行合并
-
查询每个部门的人数,没有部门的员工用NULL代表部门的名称
1 | ( |
- 在外链接里,条件写在WHERE子句里,不符合条件的记录会被过滤掉,不会被保留下来
子查询
- 嵌套在查询语句中的查询
- 子查询可以写在三个地方: WHERE, FROM, SELECT
- 只有写在FROM中的子查询是最可取的,其他地方的效率不高
WHERE子句中的多行子查询
- 可以使用IN, ALL, ANY, EXISTS关键字来处理多行表达式结果集的条件判断
1 | select ename from t_emp |
EXISTS 关键字
- 把原来在子查询之外的条件判断写到了子查询的里面
1 | SELECT SupplierName |
数据操作语言
INSERT语句
- 向数据表中写入记录,可以使一条记录也可以是多条记录
1 | insert into table_name (column_1, column_2, ...) |
- 写入多条记录
1 | insert into table_name (column_1, column_2, ...) |
IGNORE关键字
- 会让INSERT只插入数据库不存在的记录,不会报错
1 | insert ignore into table_name (...) values (...); |
UPDATE语句
1 | update table_name set column_name = value_name, ....; |
UPDATE语句的表连接
- 可以修改多张表的记录
1 | update table_1 join table_2 on condition |
DELETE 语句
1 | delete from table_name |
DELETE语句的表连接
- 删除多张表的记录
1 | delete table_1, table_2 |
事务机制
避免写入直接操作数据文件
- 利用日志来实现间接写入
- redo,undo日志
Transaction
- 全部成功或者全部失败
- 默认情况下,MySQL执行每条SQL语句都会自动开启和提交事务
- 为了让多条SQL语句纳入到一个事务之下,可以手动管理事务
start transaction;
ACID
原子性
- 全部成功或者全部失败, 没有中间状态
一致性
- 不管在任何给定时间,并发事务有多少,事务必须保证运行结果的一致性
- 事务的临时状态不会被读取
隔离性
- 事务不受其他并发事务的影响,如同再给定时间内,改事务是数据库唯一运行的事务
- 默认情况下,只能看到日志中该事物的相关数据
持久性
- 事务一旦提交,结果便是永久性的,即便发生宕机,仍然可以依靠事务日志完成数据的持久化
隔离级别
READ UNCOMMITTED
- 代表可以读取日志中其他事物的未提交的数据,即使其他事物还没有commit
set session transaction isolation level read uncommitted;
READ COMMITTED
- 代表只能读取其他事物提交的数据
set session transaction isolation level read committed;
REPEATABLE READ (默认级别)
- 事务在执行中反复读取数据,得到的结果是一致的,不会受到其他事物的影响
set session transaction isolation level repeatable read;
SERIALIZABLE
- 让事务逐一执行,不存在并发性

