I PASSED!

Getting Started
AWS Regions
- AWS has regions all aroung the world
- Names can be us-east-1, eu-west-3…
- A region is a cluster of data centers
- Most AWS services are regoin-scoped
How to choose an AWS Region?
- Compliance: with data governance and legal requirements, data never leaves a region without your explicit permission
- Proximity to customers: reduced latency
- Available services within a region: new services and new features aren’t available in every region
- Pricing: pricing varies region to region and is transparent in the service pricing page
AWS Availability Zones
- Each region has many AZs example:
- ap-southeast-2a
- ap-southeast-2b
- ap-southeast-2c
- Each AZ is one or more discrete data centers with redundant power, networking and connectivity
- they are separate from each other, so that they are isolated from disasters
- they are connected with high bandwidth, ultra low latency networking
AWS Points of Presence (Edge locations)
- Content is delivered to end users with lower latency
IAM and AWS CLI
IAM
- Identity and Access Management, Global service
- Root Account: created by default, shouldn’t be used or shared
- Users are people within your organization, and can be grouped
- Groups only contain users, not other groups
- Users don’t have to belong to a group, and user can belong to multiple groups
IAM Permissions
- Users or Groups can be assigned JSON documents called policies
- These policies define the permissions of the users
- In AWS you apply the least privilege principle, don’t give more permissions than a user needs
IAM Policies Structure
- Consist of
- Version: policy language version, always include ‘2012-10-17’
- Id: an identifier for the policy (optional)
- Statement: one or more individual statements (required)
- Statements consists of
- Sid: an identifier for the statement (optional)
- Effect: whether the statement allows or denies access (Allow, Deny)
- Principal: account/user/role to which this policy applied to
- Action: list of actions this policy allows or denies
- Resource: list of resources to which the actions applied to
- Condition: conditions for when this policy is in effect (optional)
How can users access AWS?
- AWS Management Console: protected by password + MFA
- AWS Command Line Interface: protected by access keys
- AWS SDK: for code, protected by access keys
- Access key ID = username
- Secret access key = password
IAM Roles for services
- Some AWS service will need to perform actions on your behalf
- we will assign permissions to AWS services with IAM Roles
- Common roles:
- EC2 instance roles
- lambda function roles
- roles for CloudFormation
IAM Security Tools
- IAM credentials report (account-level)
- a report that lists all your account’s users and the status of their various credentials
- IAM Access Advisor (user-level)
- Access Advisor shows the service permissions granted to a user and when those services were last accessed
- you can use this information to revise your policies
IAM Guidelines and Best practices
- Don’t user root account except for AWS account setup
- One physical user = one AWS user
- assign users to groups and assign permissions to groups
- create a strong password policy
- use and enforce the use of MFA
- create and use roles for giving permissions to AWS services
- use access keys for CLI and SDK
- Audit permissions of your account with the IAM Credential Report
- Never share IAM users and access keys
EC2
- EC2 is one of the most popular of AWS offering
- EC2 = Elastic Compute Cloud = Infrastructure as a Service
- It mainly consists in the capability of
- Renting virtual machines (EC2)
- Storing data on virtual drives (EBS)
- Distributing load across machines (ELB)
- Scaling the services using an auto-scaling group (ASG)
- Knowing EC2 is fundamental to understand how to Cloud works
EC2 Instance Types - Overview
- you can use different types of EC2 instances that are optimised for different use cases
- e.g. m5.2xlarge
- m: instance class
- 5: generation
- 2xlarge: size within the instance class
General Purpose
- Great for a diversity of workloads such as web servers or code repositories
- Balance between
- Compute
- Memory
- Networking
Compute Optimized
- Great for compute intensive tasks that require high performance processors
- Batch processing workloads
- media transcoding
- high performance web servers
- high performance computing
- scientific modeling and machine learning
- dedicated gaming servers
Memory Optimized
- Fast performance for workloads that process large data sets in memory
- high performance, relational/non-relational databases
- distributed web scale cache stores
- in memory databases optimized for BI
- applications performing real time processing of big unstructured data
Storage Optimized
- great for storage intensive tasks that require high, sequential read and write access to large data sets on local storage
- high frequency online transaction processing systems
- relational and NoSQL databases
- cache for in memory databases
- data warehousing applications
- distributed file systems
Security Groups
- the fundamental of network security in AWS
- they control how traffic is allowed into or out of our EC2 instance
- security groups only contain allow rules
- security groups rules can reference by IP or by security group (inbound/outbound rules)
Good to know
- security groups can be attached to multiple instances and one instance can have multiple security groups attach to it
- security group are locked down to a region and VPC
- security group live outside the EC2, if traffic is blocked, the EC2 instacne won’t see it (doesn’t know it tried to get in)
- if your application is not accessible (time out), then its a security group issue
- if your application gives a connection failed error, then its an application error or its not launched
- all inbound traffic is blocked by default
- all outbound traffic is authorized by default
Classic Ports to know
- 22 = SSH (Secure Shell) - log into a Linux instance
- 21 = FTP (File Transfer Protocol) - upload files into a file share
- 22 = SFTP (Secure File Transfer Protocol) - upload files using SSH
- 80 = HTTP - access unsecured websites
- 443 = HTTPS - access secured websites
- 3389 = RDP (Remote Desktop Protocol) - log into a Windows instance
EC2 Instances purchasing options
- on-demand instance: short workload, predictable pricing
- reserved, minimum 1 year:
- reserved instances: long workloads
- convertible reserved instances: long workloads with flexible instances
- scheduled reserved instances: example - every Thursday between 3 and 6 pm
- Spot instance: short workloads, cheap and can lose instances (less reliable)
- dedicated hosts: book an entire physical server, control instance placement
EC2 on demand
-
pay for what you use
- linux - billing per second, after the first minute
- all other os - billing per hour
-
has the highest cost but no upfront payment
-
no long-term commitment
-
recommended for short term and un-interrupted workloads, where you can’t predict how the application will behave.
EC2 reserved instances
- up to 75% discount compared to on demand
- reservation period: 1 year or 3 year2
- purchasing options: no upfront / partial upfront / all upfront
- reserve a specific instance type
- recommended for steady state usage applications (think database)
Convertible reserved instance
- can change the EC2 instance type
- up to 54% discount
scheduled reserved instances
- launch within time window you reserve
- when you require a fraction of day / week / month
- still commitment over 1 to 3 years
EC2 Spot instance
-
can get a discount of up to 90% compared to on demand
-
instances that you can lose at any point of time if your max price is less than the current spot price
-
the MOST cost efficient instances in AWS
-
useful for workloads that are resilient to failure
-
not suitable for critical jobs or databases
Spot instance requests
- define max spot price and get the instance while current spot price < max
- the hourly spot price varies based on offer and capacity
- if the current spot price > your max price you can choose to stop or terminate your instance with a 2 minutes grace period
- other strategy: spot block
- block spot instance during a specified time frame (1 to 6 hours) without interruptions
- in rare situations, the instance may be reclaimed
- cancel the spot instance request before terminate the spot instances
Spot fleets
- spot fleets = set of spot instances + (optional) on demand instances
- the spot fleet will try to meet the target capacity with price constraints
- define possible launch pools: instance type, OS, AZ
- can have multiple launch pools, so that the fleet can choose
- spot fleet stops launching instnaces when reaching capacity or max cost
- strategies to allocate spot instances
- lowest price: from the pool with the lowest price (cost optimization, short workload)
- diversified: distributed across all pools (great for availability, long workloads)
- capacity optimized: pool with the optimal capacity for the number of instances
- spot fleets allow us to automatically request spot instance with the lowest price
EC2 dedicated hosts
-
an Amazon EC2 dedicated host is a physical server with EC2 instance capacity fully dedicated to your use, dedicated hosts can help you address compliance requirements and reduce costs by allowing you to use your existing server-bound software licenses
-
allocated for your account for a 3 year period reservation
-
more expensive
-
useful for software that have complicated licensing model (BYOL - bring your own license)
-
or for companies that have strong regulatory or compliance needs
Elastic IP
-
when you stop and then start an EC2 instance, it can change its public IP
-
if you need to have a fixed public IP for your instance, you need an Elastic IP
-
an Elastic IP is a public IPv4 IP you own as long as you don’t delete it
-
you can attach it to one instance at a time
-
with an Elastic IP, you can mask the failure of an instance or software by rapidly remapping the address to another instance in your account (not common)
-
you can only have 5 Elastic IP in your account
-
Overall, try to avoid using Elastic IP
- they often reflect poor architectrual decisions
- instead, use a random public IP and register a DNS name to it
- use a load balancer and don’t use a public IP
Placement Groups
- Sometimes you want control over the EC2 instance placement strategy
- when you create a placement group, you specify one of the following strategies for the group
- Cluster: clusters instances into a low latency group in a single AZ
- Spread: spreads instances across underlying hardware (max 7 instances per group per AZ) - critical applications
- partition: spreads instances across many different partitions (which rely on different sets of racks) within an AZ, Scales to 100 of EC2 instances per group (Hadoop, Cassandra, Kafka), the instances in a partition do not share racks with the instances in the other partitions, a partition failure can affect many EC2 but won’t affect other partitions
Elastic Network Interfaces (ENI)
- logical component in a VPC that represents a virtual network card
- the ENI can have the following attributes
- Primary private IPv4, one or more secondary IPv4
- One Elastic IP per private IPv4
- one public IPv4
- one or more security groups
- a MAC address
- you can create ENI independently and attach them on the fly on EC2 instances for failover
- bound to a specific AZ
EC2 Hibernate
-
Stop: the data on disk (EBS) is kept intact in the next start
-
Terminate: any EBS volums (root) also setup to be destroyed is lost
-
First start: the OS boots and the EC2 user data script is run
-
Following starts: the OS boots up
-
the your application starts, caches get warmed up and that can take time
-
Introducing EC2 Hibernate
- RAM state is preserved
- the instance boot is much faster (the OS is not stopped / restarted)
- under the hood: the RAM state is written to a file in the root EBS volume
- the root EBS volume must be encrypted
-
Use cases
- long running process
- saving the RAM state
- servcies that take time to initialize
EC2 Nitro
- underlying platform for the next generation of EC2 instances
- new virtualization technology
- allows for better performance
- better networking options
- Higher Speed EBS
- better underlying security
EC2 vCPU
- EC2 instance comes with a combination of RAM and vCPU
- in some cases, you may want to change the vCPU options
- change the number of CPU cores
- chagne the number of vCPUs (threads) per core
- only specified during instance launch
EC2 capacity reservations
- ensure you have EC2 capacity when needed
- manual or planned end date for the reservation
- no need for 1 or 3 year commitment
- capacity access is immediate, you get billed as soon as it starts
- combine with reserved instances and savings plans to do cost saving
EC2 EBS
- an EBS volume is a network drive you can attach to your instances while they run
- it allows your instances to persist data, even after their termination
- they can only be mounted to one instance at a time (in some cases, some EBS can be attached to multiple EC2 instances at same time)
- they are bound to a specific AZ
- think of them as a network USB stick
EBS volume
- its a network drive
- it uses the network to communicate the instance, which means there might be a bit of latency
- it can be detached from an EC2 instance and attached to another one quickly
- its locked down to an AZ
- an EBS volume in us-east-1a cannot be attached to an instance in us-east-1b
- to move a volume across, you first need to snapshot it
- have a provisioned capacity
- you get billed for all the provisioned capacity
- you can increase the capacity of the drive over time
EBS volume types
- gp2 / gp3: general purpose SSD
- gp3: newer generation, IOPS and throughput are independet
- gp2: IOPS and throughput are linked
- io1 / io2: highest performance SSD
- st1: low cost HDD, for throughput intensive workloads
- sc1: lowest cost HDD
- EBS volumes are characterized in Size / Throughput / IOPS
EBS multi-attach - io1/io2 family
- attach the same EBS volume to multiple EC2 instances in the same AZ
- each instance has full read and write permissions to the volume
- applications must manage concurrent write operations
- must use a file system thta’s cluster-aware
EBS encryption
- when you create an encrypted EBS volume, you get the following
- data at rest is encrypted inside the volume
- all the data in flight mobing between the instance and the volume is encrypted
- all snapshots are encrypted
- all volumes created from the snapshot are encryped
- encryption and decryption are handled transparently
- encryption has a minimal impact on latency
- EBS encryption leverages keys from KMS (AES-256)
- copying an unencrypted snapshot allows encryption
EBS RAID
RAID 0
- increase performance
- combining 2 or more volumes and getting the total disk space and I/O
- but if one disk fails, all the data is failed
- using this, we can have a very big disk with a lot of IOPS
RAID 1
- increase fault tolerance
- mirroring a volume to another
- we have to send the data to two EBS volume at the same time (2 * network)
EBS delete on termination
- controls the EBS behaviour when an EC2 instance terminates
- by default, the root EBS volume is delete (attribute enabled)
- by default, any other attached EBS volume is not deleted (attribute disabled)
- this can be controlled by the AWS console / CLI
- use case: preseve root volume when instance is terminated (disable the attribute)
EBS Snapshots
- make a backup (snapshot) of your EBS volume at a point of time
- not necessary to detach volume to do snapshot, but recommended
- can copy snapshots across AZ or Region
- can create volume from snapshot
EFS - Elastic File System
- Managed NFS (network file system) that can be mounted on many EC2
- EFS works with EC2 instances in multi-AZ
- highly avialble, scalable, expensive, pay per use
- uses security group to control access to EFS
- compatible with Linux based AMI (not Windows)
- encryption at rest using KMS
- to mount EFS to EC2, you need to add EC2 security group as a inbound rule in EFS security group
Performance and Storage Class
- Performance mode
- general purpose
- MAX I/O
- Throughput mode
- bursting
- provisioned
- Storage tiers
- standard
- infrequent access, cost to retrieve files, lower price to store
AMI Overview
- Amazon Machien Image
- a customization of an EC2 instance
- you add your own software, configuration, operating system etc…
- faster boot / configuration time because all your software is pre-packaged
- AMI are built for a specific region and can be copied across regions
- you can launch EC2 instance from
- public AMI: provided by AWS
- your own AMI: you make and maintain them yourself
- AWS marketplace AMI: an AMI someone else made
EC2 instance store
- EBS volumes are network drives with good but limited performance
- if you need a high performance hardware disk, use EC2 instance store
- better I/O performance
- EC2 instance store lose their storage if they are stopped (ephemeral)
- good for buffer / cache / scratch data / temporary content
- risk of data loss if hardware fails
- backups and replication are your responsibility
EC2 Metadata
- AWS EC2 instance metadata is powerful but one of the least known features to developers
- it allows EC2 instance to learn about themselves without using an IAM role for that purpose
- the URL is
http://169.254.169.254/latest/meta-data - you can retrieve the IAM role name from the metadata, but you CANNOT retrieve the IAM policy
Elastic Load Balancer
What is load balancing?
- load balancers are servers that forward internet traffic to multiple servers (EC2 instances) downstream
Why use a load balancer?
-
Spread load across multiple downstream instances
-
expose a single point of access (DNS) to your application
-
seamlessly handle failures of downstream instances
-
do regular health checks to your instances
-
provide SSL termination (HTTPS) for your websites
-
enforce stickness with cookies
-
high availability across zones
-
separate public traffic from private traffic
-
An ELB is a managed load balancer
- AWS guarantees that it will be working
- AWS takes care of upgrades, maintenance, high availability
- AWS provides only a few configuration knobs
-
it costs less to setup your own load balancer but it will be a lot more effort on your end
-
it is integrated with many AWS offering / services
Health Checks
- Health Checks are crucial for load balancers
- they enable the load balancer to know if instances it forwards traffic to are available to reply to requests
- the health check is done on a port and a route (/health is common)
- if the response is not 200, then the instance is unhealthy
Classic Load Balanceers (v1)
- supports TCP (layer 4), HTTP and HTTPS (layer 7)
- health checks are TCP or HTTP based
Application Load Balancer (v2)
- Application load balancer is layer 7 (HTTP)
- load balancing to multiple HTTP applications across machines (target groups)
- load balancing to multiple applications on the same machine (containers)
- support for HTTP/2 and WebSocket
- Support redirects (from HTTP to HTTPS)
- Routing tables to differnt target groups
- routing based on path in URL (example.com/users & example.com/posts)
- routing based on hostname in URL (one.example.com & other.example.com)
- routing based on query string, headers (example.com/users?id=123&other=false)
- ALB are a great fit for micro services and container based application (Docker and Amazon ECS)
- Has a port mapping feature to redirect to a dynamic port in ECS
- in comparison, we would need multiple CLB, one for each application
Target Groups
- EC2 instances can be managed by an Auto Scaling Group - HTTP
- ECS tasks (managed by ECS itself) - HTTP
- Lambda function - HTTP request is translated into a JSON event
- IP addresses - must be private IPs
- ALB can route to multiple target groups
- health checks are at the target group level
Network Load Balancer (v2)
- network load balancer (layer 4)
- forward TCP and UDP traffic to your instance
- handle millions of request per second
- less latency ~ 100 ms (vs 400 ms for ALB)
- NLB has one static IP per AZ, and supports assigning Elastic IP (helpful for whitelisting specific IP)
- NLB are used for extreme performance, TCP or UDP traffic
- Not included in AWS free tier
Sticky Sessions (Session Affinity)
-
it is possible to implement stickness so that the same client is always redirected to the same instance behind a load balancer
-
this works for CLB and ALB
-
the cookie used for stickness has an expiration date you control
-
use case: make sure the user doesn’t lost his session data
-
enabling stickness may bring imbalance to the load over the backend EC2 instances
-
Application based cookies
- custom cookie
- generated by the target
- can include any custom attributes required by the application
- cookie name must be specified individually for each target group
- don’t use AWSALB, AWSALBAPP, AWSALBTG (reserved for use by the ELB)
- application cookie
- generated by the load balancer
- cookie name is AWSALBAPP
- custom cookie
-
Duration based cookie
- cookie generated by the load balancer
- cookie name is AWSALB for ALB, AWSELB for CLB
Cross Zone Load Balancing
- each load balancer instance distribute evenly across all registered instances in all AZ
- ALB
- always on (can’t be disabled)
- no charges for inter AZ data
- NLB
- disabled by default
- you pay charges for inter AZ data if enabled
- CLB
- Through console => enabled by default
- through CLI / API => disabled by default
- no charges
SSL/TLS
-
an SSL certificate allows traffic between your clients and your load balancer to be encrypted in transit
-
SSL refers to Secure Sockets Layer, used to encrypt connections
-
TLS refers to Transport Layer Security, which is a newer version
-
TLS certificate are mainly used, but people still refer as SSL
-
public SSL certificates are issued by Certificate Authorities (CA)
-
SSL certificates have an expiration date and must be renewed
-
the load balancer uses an X.509 certificate (SSL/TLS server certificate)
-
you can manage certificates using ACM (AWS Certificate Manager)
-
You can create upload your own certificate
-
HTTPS listner
- you must specify a default certificate
- you can add an optional list of certs to support multiple domains
- clients can use SNI (Server Name Indication) to specify the host name they reach
- ability to specify a security policy to support older version of SSL/TLS
SSL - Server Name Indication
- SNI solves the problem of loading multiple SSL certificate onto one web server (to serve multiple website)
- its newer protocol, and requires the client to indicate the hostname of the target server in the initial SSL handshake
- the server will then find the correct certificate, or return the default one
- Only works for ALB and NLB, CloudFront
- doesn’t work for CLB
ELB Connection Draining
- Time to complete in-flight requests while the instance is de-registering or unhealthy
- stops sending new requests to the instance which is de-registering
- between 1 to 3600 seconds, default is 300 seconds
- can be disabled (set to zero)
- set to a low value if your requests are short
Auto Scaling Group
-
in real life, the load on your websites and application can change
-
in the cloud, you can create and get rid of servers very quickly
-
the goal of an Auto Scaling Group is to
- scale out to match an increased load
- scale in to match an decreased load
- ensure we have a minimum and maximum number of machines running
- automatically register new instances to a load balancer
ASG attributes
- A launch configuration
- AMI + instance type
- EC2 user data
- EBS volumes
- Security groups
- SSH key pair
- min size / max size / initial capacity
- network + subnets information
- load balancer information
- scaling policies
Auto Scaling Alarms
- it is possible to scale an ASG based on CloudWatch alarms
- an alarm monitors a metric (such as average CPU)
- metrics are computed for the overall ASG instances
Auto Scaling New Rules
- it is now possible to define better auto scaling rules that are directly managed by EC2
- target average CPU usage
- number of requests on the ELB per instance
- average network in
- average network out
- these rules are easier to setup and can make more sense
Auto Scaling Custom Metric
- send custom metric from application on EC2 to CloudWatch
- Create CloudWatch alarm to react to low / high values
- use the CloudWatch alarm as the scaling policy for ASG
Good to know
- scaling policies can be on CPU, network… and can even be on custom metrics or based on a schedule
- ASGs use launch configurations or launch templates
- to update an ASG, you must provide a new launch configuration / launch template
- IAM roles attached to an ASG will get assigned to EC2 instances
- ASG are free, you pay for the underlying resources being launched
- having instances under an ASG means that if they get terminated for whatever reason, the ASG will automatically create a new one as a replacement.
- ASG can terminate instances marked as unhealthy by an ELB (and then replace them)
Auto Scaling Groups - Dynamic Scaling Policies
- target tracking scaling
- most simple and easy to setup
- example: I want to average ASG CPU to stay at around 40%
- Simple / Step Scaling
- When a CloudWatch alarm is triggered (example: CPU > 70%), then add 2 units
- when a CloudWatch alarm is triggered (example: CPU < 30%), then remove 1 unit
- Scheduled Actions
- anticipate a scaling based on known usage patterns
- example: increase the min capacity to 10 at 5pm on Fridays
- predictive scaling
- continuously forecast load and schedule scaling ahead
Good metrics to scale on
- CPU Utilization
- average CPU utilization across your instances
- Request Count Per Target
- to make sure the number of requests per EC2 instances is stable
- Average network in / out
- if your application is network bound (heavy downloads / uploads)
- Any custom metric that you push using CloudWatch
Scaling Cooldowns
- After a scaling activity happens, you are in the cooldown period (default 300 seconds)
- during the cooldown period the ASG will not launch or terminate additional instances (to allow for metrics to stablize)
- advice: use a ready to use AMI to reduce configuration time in order to be serving request faster and reduce the cooldown period
ASG default termination policy
- Find the AZ which has the most number of instances
- if there are multiple instances in the AZ to choose from, delete the one with the oldest launch configuration
- ASG tries to balance the number of instances across AZ by default
ASG lifecycle hooks
- by default as soon as an instance is launched in an ASG its inservice
- you have the ability to perform extra steps before the instance goes in service (pending state)
- you have the ability to perform extra actions before the instance is terminated (terminating state), like extract logs, tools etc…
ASG launch template vs Launch configuration
- both
- ID of the AMI, the instance type, a key pair, security groups, and the other parameters that you use to launch EC2 instances
- Launch Configuration
- must be re-created every time
- launch template
- can have multiple versions
- create parameters subsets (partial configuration for re-use and inheritance)
- provision using both on demand and stop instances
- can use T2 unlimited burst feature
- recommended by AWS going forward
RDS
- RDS stands for relational database service
- its a managed DB service for DB use SQL as a query language
- it allows you to create databases in the cloud that are managed by AWS
- Postgres
- MySQL
- MariaDB
- Oracle
- Microsoft SQL Server
- Aurora (AWS Proprietary database)
Advantage over using RDS vs deploying DB on EC2
- RDS is a managed service
- automated provisioning, OS patching
- continuous backups and restore to specific timestamp (point in time restore)
- monitoring dashboards
- read replicas for improved read performance
- multi AZ setup for DR (Disaster Recovery)
- maintenance windows for upgrades
- scaling capability (vertical or horizontal)
- storage backed by EBS
- but you can’t SSH into your RDS instance (its managed by AWS)
RDS backups
- backups are automatically enabled in RDS
- automatically backups
- daily full backup of the database (during the maintenance windows)
- transaction logs are backed up by RDS every 5 minutes
- ability to restore to any point in time (from oldest backup to 5 minutes ago)
- 7 days retention (can be increased to 35 days)
- DB snapshots
- manually triggered by the user
- retention of backup for as long as you want
RDS storage auto scaling
- helps you increase storage on your RDS DB instance dynamically
- when RDS detects you are running out of free database storage, it scales automatically
- avoid manually scaling your database storage
- you have to set maximum storeage threshold (maximum limit for DB storage)
- automatically modify storage if
- free storage is less than 10% of allocated storage
- low storage lasts at least 5 minuts
- 6 hours have passed since last modification
- useful for applications with unpredicatable workloads
- supports all RDS database engines (MariaDB, MySQL, PostgreSQL, SQL server, Oracle)
Read Replicas for read scalability
- up to 5 read replicas
- within AZ
- cross AZ
- cross region
- replication is ASYNC, so reads are eventually consisent, possible to read old data
- replicas can be promoted to their own DB
- applications must update the connection string to leverage read replicas
Read replicas - use case
- you have a production database that is taking on normal load
- you want to run a reporting application to run some analytics
- you create a read replica to run the new workload there
- the production application is unaffected
- read replicas are used for SELECT only kind of operations (not DELETE, INSERT, UPDATE)
Network cost
- in AWS there is a network cost when data goes from one AZ to another
- for RDS read replicas within the same region, you don’t pay that fee
- for read replicas across regions, you need to pay
Multi AZ disaster recovery
- SYNC replication
- one DNS name - automatic app failaover to standby
- increase availability
- failover in case of loss of AZ, loss of network, instance or storage failure
- no manual intervention in apps
- not used for scaling (not handle traffic, only take over when master RDS fail)
- NOTE: the read replicas can be setup as Multi AZ for disaster recovery
RDS - from single AZ to multi AZ
- zero downtime operation (no need to stop the DB)
- just click on modify for the database
- the following happens internally
- a snapshot is taken
- a new DB is restored from the snapshot in a new AZ
- synchronization is established between the two databases
RDS security - encryption
- at rest
- possibility to encrypt the master and read replicas with AWS KMS - AES-256 encryption
- encryption has to be defined at launch time
- if the master is not encrypted, the read replica cannot be encrypted
- Transparent Data Encryption (TDE) available for Oracle and SQL server
- in flight encryption
- SSL certificate to encrypt data to RDS in flight
- provide SSL options with trust certificate when connecting to database
Encryption operations
- Encrypting RDS backups
- snapshots of un-encrypted RDS databases are un-encrypted
- snapshots of encrypted RDS database are encrypted
- can copy a snapshot into an encrypted one
- to encrypt an un-encrypted RDS database
- create a snapshot of the un-encrypted database
- copy the snapshot and enable encryption for the snapshot
- restore the database from the encrypted snapshot
- migrate applications to the new database and delete the old database
RDS security - network and IAM
- network security
- RDS database are usually deployed within a private subnet, not in a public one
- RDS security works by leveraging security groups (the same concept as for EC2 instances) - it controls which IP / security group can communicate with RDS
- access management
- IAM policies help control who can manage AWS RDS (through the RDS API)
- traditional username and password can be used to login into the database
- IAM based authentication can be used to login into RDS for MySQL and PostgreSQL
RDS - IAM authentication
- IAM database authentication works with MySQL and PostgreSQL
- you don’t need a password, just an authentication token obtained through IAM and RDS API calls
- auth token has a lifetime of 15 minutes
- benefits
- network in / out must be encrypted using SSL
- IAM to centainly manage users instead of DB
- can leverage IAM roles and EC2 instance profiles for easy integration
Amazon Aurora
- Aurora is a proprietary technology from AWS (not open sourced)
- Postgres and MySQL are both supported as Aurora DB (that means your drivers will work as if Aurora was a Postgres or MySQL database)
- Aurora is AWS cloud optimized and claims 5x performance improvement over MySQL on RDS, over 3x performance of Postgres on RDS
- Aurora storage automatically grows from 10 GB to 64 TB
- Aurora can have 15 replicas while MySQL has up to 5, and the replication process is faster
- failover in Aurora is instantaneous
- Aurora costs more then RDS (20% more), but is more efficient
Aurora High Availability and Read Scaling
- 6 copies of your data across 3 AZ
- 4 copies out of 6 needed for writes
- 3 copies out of 6 needed for reads
- self healing with peer to peer replication
- storage is striped across 100s of volumes
- one Aurora instance takes writes (master)
- automated failover for master in less than 30 seconds
- master + up to 15 Aurora read replicas serve reads
- support for cross region replication
Aurora - Custom Endpoints
- define a subset of Aurora instances as a custom endpoint
- example: run analytical queries on specific replicas
- the reader endpoint is generally not used after defining custom endpoints
Aurora serverless
- automated database instantiation and auto scaling based on actual usage
- good for infrequent intermittent or unpredictable workloads
- no capacity planning needed
- pay per second, can be more cost effective
Aurora Multi-Master
- in case you want immediate failover for write node (HA)
- every node does Read and write - vs - promoting a read replica as the new master (faster failover)
Amazon ElastiCache
- the same way RDS is to get managed relational databases
- elastiCache is to get managed Redis or Memcached
- caches are in memory databases with really high performance, low latency
- helps reduce load off databases for read intensive workloads
- helps make your application stateless
- AWS takes care of OS maintenance / patching, optimization, setup, configuration, monitoring, failure recovery and backups
- using ElastiCache involves heavy application code changes
DB Cache
- applications queries ElastiCache, if not available, get from RDS and store in ElastiCache
- htlps relieve load in RDS
- Cache must have an invalidation strategy to make sure only the most current data is used in there (LRU, LFU)
User session store
- user logs into any of the application
- the application wrties the session data into ElastiCache
- the user hits another instance of our application
- the instance retrieve the session data and the user is already logged in
Redis
- Multi AZ witi auto faliover
- read replicas to scale reads and have High Availability
- data durability using AOF persistence
- backup and restore features
Memcached
- multi-node for partitioning of data (sharding)
- no high availability (replication)
- non persistent
- no backup and restore
- multi-threaded architecture
Patterns for ElastiCache
- Lazy loading
- all the read data is cached, data can become stale in cache
- write through
- adds or update data in the cache when written to a DB (no stale data)
- session store:
- store temporary session data in a cache (using TTL features)
Reids use case
- Gaming leaderboard
- Redis Sorted sets guarantee both uniqueness and element ordering
- each time a new element added, its ranked in real time, then added in correct order
Route 53
- route 53 is a managed DNS (domain name system)
- DNS is a collection of rules and records which helps clients understand how to reach a server through its domain name
- in AWS, the most common records are
- A: hostname => IPv4
- AAAA: hostname => IPv6
- CNAME: hostname => hostname
- Alias: hostname => AWS resource
Overview
- route 53 can use
- public domain names you own
- private domain names that can be resolved by your instances in your VPCs
- Route 53 has advanced features such as
- load balancing (through DNS, also called client load balancing)
- health checks
- routing policy: simple, failover, geolocation, latency, weighted…
- you pay $0.5 per month per hosted zone
- user will first send DNS request (http://myapp.mydomain.com) to route 53 asking for IP address
- route 53 will response will the ip address of that DNS and a TTL
- user browser will then send the HTTP request to the correct IP to reach the server
- next time when the user send DNS request, if the last request is not expire (check the TTL), browser will directly go to the last saved IP address, save traffic for route 53
CNAME vs Alias
- AWS resource (load balancer, cloudfront…) expose an AWS hostname and you want myapp.mydomain.com
- CNAME
- points a hostname to any other hostname
- only for non root domain (something.mydomain.com)
- Alias
- points a hostname to an AWS resource
- works for root domain and non root domain (mydomain.com)
- free of charge
- native health check
Simple Routing policy
- use when you need to redirect to a single resource
- you can’t attach health checks to simple routing policy
- if multiple values (IP addresses) are returned, a random one is chosen by the client (client side load balancing)
Weighted routing policy
- control the percentage of the requests that go to specific endpoint
- helpful to test percentage of traffic on new app version for example
- helpful to split traffic between two regions
- can be associated with health checks
- but on the client side the browser is not aware that it has multiple weighted endpoints in the backend
Latency routing policy
- redirect to the server that has the least latency close to user
- super helpful when latency of users is a priority
- latency is evaluated in terms of user to designated AWS region
- Germany may be redirected to the US (if that’s the lowest latency)
Route 53 health checks
- have X health checks failed => unhealthy (default 3)
- have X health checks passed => healthy (default 3)
- default health checks interval : 30 seconds (can set to 10 seconds with higher cost)
- about 15 health checkers will the the endpoint health in the background (from different regions)
- one request every 2 seconds on average (30 / 15)
- can have HTTP, TCP, and HTTPS health checks (no SSL verification)
- possible to integrate health check with CloudWatch
- health checks can be linked to route 53 DNS queries
GeoLocation routing policy
- different from latency based
- this is routing based on user location
- here we specify traffic from the UK should go to this specific IP
- should create a default policy (in case there is no match on location)
Geoproximity routing policy
- route traffic to your resources based on the geographic location of users and resources
- ability to shift more traffic to resources based on the defined bias
- to change the size of the geographic region, specify bias values
- to expand (1 to 99) - more traffic to the resources
- to shrink (-1 to -99) - less traffic to the resources
- resources can be
- AWS resources (specify AWS region)
- non-AWS resources (specify latitude and longitude)
- you must use route 53 traffic flow (advanced) to use this feature
Multi value routing policy
- use when routing traffic to multiple resources
- want to associate a route 53 health checks with records
- up to 8 healthy records are returned for each multi value query
- multi value is not a substitute for having an ELB
- client browser will randomly choose a healthy record from returned records (client side fault tolerance)
Route 53 as a Registrar
-
a domain name registrar is an organization that manages the reservation of internet domain names
- GoDaddy
- Google Domains
-
Domain registrar != DNS
-
if you buy your domain on 3rd party website, you can still use route 53
- create a hosted zone in route 53
- update NS records on 3rd party website to use route 53 name servers (all 4 of them)
Classic Solutions Architecture
Stateful App with shopping cart
- ELB sticky sessions
- web clients for storing cookies and making our web app stateless
- ElastiCache
- for storing sessions (alternative: DynamoDB)
- for caching data from RDS
- Multi AZ
- RDS
- for storing user data
- read replicas for scaling reads
- multi AZ for disaster recovery
- tight security with security groups referencing each other
Instantiating Applications Quickly
- EC2 instances
- use a golden AMI: install your applications, OS dependencies, beforehand and launch your EC2 instance from the golden AMI
- bootstrap using user data: for dynamic configuration, use User Data scripts
- Hybrid: mix golden AMI and User Data (Elastic Beanstalk)
- RDS databases
- restore from a snapshot: the database will have schemas and data ready
- EBS volume:
- restore from a snapshot, the disk will already be formatted and have data
Beanstalk
Developer problems on AWS
-
managing infrastructure
-
deploying code
-
configuring all the databases, load balancers, etc…
-
scaling concerns
-
most web apps have the same architecture (ALB + ASG)
-
all the developers want is for their code to run
-
possibly, consistently across different applications and environments
Elastic Beanstalk - overview
- Elastic Beanstalk is a developer centric view of deploying an application on AWS
- it uses all the component’s we have seen before: EC2, ASG, ELB, RDS…
- managed service
- automatically handles capacity provisioning, load balancing, scaling, application health monitoring, instance configuration…
- just the application code is the responsiblity of the developer
- we still have full control over the configuration
- Beanstalk is free but you pay for the underlying instances
Elastic Beanstalk - components
- application
- collectioin of Elastic Beanstalk components (environments, versions, configurations…)
- application version
- an iteration of your application code
- environment
- collection of AWS resources running an application version (only one application version at a time)
- Tiers
- web server environment tier
- worker environment tier
- you can create multiple environments (dev, test, prod…)
S3
Buckets
- Amazon S3 allows people to store objects in buckets
- buckets must have a globally unique name
- buckets are defined at the region level
- naming convention
- No uppercase
- no underscore
- 3-63 characters long
- not an ip
- must start with lowercase letter or number
Objects
-
objects (files) have a key
-
the key is the FULL path
- s3:"//my-bucket/my_folder/another_folder/my_file.txt
- key is: my_folder/another_folder/my_file.txt
- prefix is: my_folder/another_folder/
- object name is: my_file.txt
-
there is no conecpt of directories within buckets
-
just keys with very long names that contain slashes
-
object values are the content of the body
- max object size is 5TB
- if uploading more than 5GB, must use multi-part upload
-
metadata (list of text key / value pairs, system or user metadata)
-
Tags (Unicode key / value pair - up to 10) - useful for security / lifecycle
-
Version ID (if versioning is enabled)
Versioning
- you can version your files in Amazon S3
- it is enabled at the bucket level
- same key overwrite will increment the version
- it is best pratice to version your buckets
- protect against unintended deletes (ability to restore a version)
- easy roll back to previous version
- notes
- any file that is not versioned prior to enabling versioning will have version
null - suspending versioning does not delete the previous versions
- any file that is not versioned prior to enabling versioning will have version
Encryption for objects
- SSE-S3: encrypts S3 object using keys handled and managed by AWS
- SSE-KMS: leverage AWS KMS service to manage encryption keys
- SSE-C: when you want to manage your own encryption keys
- client side encryption
- it is important to understand which ones are adapted to which situation for the exam
S3 Default Encryption
- one way to force encryption is to use a bucket policy and refuse any API call to PUT an S3 object without encryption headers
- another way is to use the default encryption option in S3
- note: bucket policies are evaluated before default encryption
- e.g. if you have a bucket policy to reject all un-encrypted files from being upload to S3, then you can’t upload un-encrypted file even if you have the default encryption enabled.
SSE-C
- Amazon S3 does not store the encryption key you provide
- HTTPS must be used (because you need to send the key in the request)
- Encryption key must provided in HTTP headers, for every request
Client side encryption
- client library such as the Amazon S3 Encryption client
- clients must encrypt the data themselves before sending to S3
- clients must decrypt the data themselves when retrieving the data from S3
- customer fully manages the keys and encryption cycle
Encryption in transit (SSL/TLS)
- Amazon S3 exposes
- HTTP endpoint, non encrypted
- HTTPS endpoint, encryption in flight
- You are free to use the endpoint you want, but HTTPS is recommended
- most clients would use the HTTPS endpoint by default
- HTTPS is mandatory for SSE-C (because you need to send the key in the request)
Security
-
User based
- IAM policies: which API calls should be allowed for a specific user from IAM console
-
Resource based
- bucket policies: bucket wide rules from the S3 console - allows cross account
- Object ACL: finer grain
- Bucket ACL: less common
-
Note: an IAM principal can access an S3 object if
- the user IAM permissions allow it OR the resource policy ALLOW it
- AND there is no explicit DENY
-
JSON based policies
- Resources: buckets and objects
- Actions: Set of API to Allow or Deny
- Effect: Allow / Deny
- Principal: the account or user to apply the policy to
-
use S3 bucket for policy to
- Grant public access to the bucket
- Force objects to be encrypted at upload
- Grant access to another account (cross account)
CORS
- An origin is a scheme, host, and port
- CORS means Cross-Origin Resource Sharing
- Web browser based machanism to allow requests to other origins while visiting the main origin
- the requests won’t be fulfilled unless the other origin allows for the requests, using CORS Headers (
Access-Control-Allow-Origin) - if a client does a cross-origin request on our S3 bucket, we need to enable the correct CORS headers
- you can allow for a specific origin or * for all origins
S3 Access logs
- for audit purpose, you may want to log all access to S3 buckets
- any request made to S3, from any account, authorized or denied, will be logged into another S3 bucket
- that data can be analyzed using data analysis tools later (Amazon Athena)
S3 Replication (Cross-Region or Same Region)
-
Must enable versioning in source and destination
-
cross region replication
-
same region replication
-
buckets can be in different accounts
-
copying is asynchronous
-
must give proper IAM permissions to S3
-
After activating, only new objects are replicated (existing objects will not be replicated)
-
For DELETE operations
- can replicate delete markers from source to target (optional setting)
- deletions with a version ID are not replicated (to avoid malicious deletes)
-
there is not chaining of replication
- if bucket one has replicatio into bucket two, which has replicatioin into bucket three
- then objects created in bucket one are not replicated to bucket three
S3 Pre-signed URL
- can generate pre-signed URLs using SDK or CLI
- valid for a default of 3600 seconds
- users given a pre-signed URL inherit the permissions of the person who generated the URL for GET / PUT
S3 Storage Class
Standard - General Purpose
- High durability of objects across multiple AZ
- 99.99% availability over a given year
- sustain 2 concurrent facility failure
- use case: big data analytics, mobile and gaming applications, content distribution…
Standard - IA
- suitable for data that is less frequently accessed, but requires rapid access when needed
- 99.9% availability
- low cost compared to GP
- use cases: as a data store for disater recovery, backups
One Zone - IA
- Same as IA but data is stored in a single AZ
- 99.5% availability
- low latency and high throughput performance
- supports SSL for data at transit and encryption at rest
- low cost compared to IA
- use cases: storing secondary backup copies of on-premise data, or storing data you can re-create
Intelligent Tiering
- same low latency and high throughput performance of S3 standard
- small monthly monitoring and auto-tiering fee
- automatically moves objects between two access tiers based on changing access patterns
- resilient against events that impact an entire AZ
Amazon Glacier
- low cost object storage meant for archiving / backup
- data is retained for the longer term (10+ years)
- alternative to on-premise magnetic tape storage
- cost per storage per month + retrieval cost
- each item in glacier is called archive
- archives are stored in Vaults
Amazon Glacier and Glacier Deep Archive
- Amazon Glacier - 3 retrieval options
- expedited (1 to 5 minues)
- standard (3 to 5 hours)
- bulk (5 to 12 hours)
- minimum storage duration of 90 days
- Amazon Glacier Deep Archive
- Standard (12 hours)
- Bulk (48 hours)
- Minimum storage duration of 180 days
S3 Lifecycle Rules
- Transition actions
- it defines when objects are transitioned to another storage class
- e.g. move objects to Standard IA class 60 days after creation
- e.g. move to Glacier for archiving after 6 months
- Expiration actions
- configure to expire (delete) after some time
- e.g. access log files can be set to delete after a 365 days
- e.g. can be used to delete old versions of files (if versioning is enabled)
- e.g. can be used to delete incomplete multi-part uploads
S3 Analytics - Storage Class Analysis
- You can setup S3 analytics to help determine when to transit objects from Standard to Standard IA
- does not work for One Zone - IA or Glacier
S3 Select and Glacier Select
- retrieve less data using SQL by performing server side filtering
- can filter by rows and columns
- less network transfer, less CPU cost client-side
S3 Event notifications
- can create as many events as desired
- SNS
- SQS
- Lambda function
- S3 event notifications typically deliver events in seconds but can sometimes take a minute or longer
- if two writes are made to a single non-versioned object at the same time, it is possible that only a single event notification will be sent
- if you want to ensure that an event notification is sent for every successful write, you can enable versioning on your bucket.
- Your S3 bucket needs to have permission to send message to SQS queue
S3 Requester Pays
- in general, bucket owners pay for all S3 storage and data transfer costs associated with their buckets
- with Requester Pays buckets, the requester instead of the bucket owner pays the cost of the request and the data download from the bucket
- helpful when you want to share large datasets with other accounts
- the requester must be authenticated in AWS (cannot be anonymous)
Glacier Vault Lock
- Adopt a WORM (Write Once Read Many) model
- lock the policy for future edits (can no longer be changed)
- helpful for compliance and data retention
S3 Object Lock (versioning must be enabled)
- adopt a WORM (Write Once Read Many) model
- block an object version deletion for a specified amount of time
- object retention
- retention period: specifies a fixed period
- legal hold: same protection, no expiry date
- Modes
- Governance mode: users can’t overwrite or delete an object version or alter its lock settings unless they have special permissions
- Compliance mode: a protected object version can’t be overwritten or deleted by any user, including the root user. When an object is locked in compliance mode, its retention mode can’t be changed and its retention period can’t be shortened.
AWS Athena
- serverless service to perform analytics directly against S3 files
- uses SQL language to query the files
- has a JDBC / ODBC driver (for BI tools)
- charged per query and amount of data scanned
- supports CSV, JSON, ORC, Avro, and Parquet (built on Presto)
- use cases: BI / Analytics / reporting / Logs / CloudTrail trails etc…
AWS CloudFront
- CDN
- improves read performance, content is cached at the edge loctions
- 216 point of presence globally (edge locations)
- DDoS protection, integration with Shield, AWS web application firewall
- can expose external HTTPS and can talk to internal HTTPS backends
Origins
- S3 bucket
- for distributing files and caching them at the edge
- enahnced security with CloudFront OAI (Origin Access Identity), this can block access directly to S3
- CloudFront can be used as an ingress (to upload files to S3)
- Custom Origin (HTTP)
- Application Load Balancer
- EC2 instance
- S3 Website (must first enable the bucket as a static S3 website)
- Any HTTP backend you want
CloudFront vs S3 Cross Region Replication
- CloudFront
- Global Edge Network
- files are cached for a TTL
- great for static content that must be available everywhere, maybe outdated for a while
- S3 Cross Region Replication
- must be setup for each region you want replication to happen
- files are updated in near real time
- read only
- great for dynamic content that needs to be available at low latency in few regions
CloudFront Signed URL / Signed Cookies
- you want to distribute paid share content to premium users over the world
- we can use CloudFront Signed URL / Cookie, we attach a policy with
- includes URL expiration
- includes IP ranges to access the data from
- Trusted Signers (which AWS accounts can create signed URLs)
- Signed URL: access to individual files (one signed URL per file)
- Signed Cookies: access to multiple files (one signed Cookie for many files)
Process
- user authenticate and authorized to the application
- the application send request to CloudFront to generate Signed URL / Cookie
- the application send the signed URL / Cookie back to user
- user use the signed URL / Cookie to access the file in CloudFront
- CloudFront fetch the file from S3 to the user
CloudFront Signed URL vs S3 Pre-signed URL
- CloudFront Signed URL
- Allow access to a path, no matter the origin
- account wide key pair, only the root can manage it
- can filter by IP, path, date, expiration
- can leverage caching features
- S3 Pre-signed URL
- issue a request as the person who pre-signed the URL
- uses the IAM key of the signing IAM principal
- limited lifetime
CloudFront - Price Class
- You can reduce the number of edge locations for cost reduction
- 3 price classes
- price class all: all regions
- price class 200: most regions, but excludes the most expensive regions
- price class 100: only the least expensive regions
CloudFront - Multiple Origins
- to route to different kind of origins based on the content type
- e.g. one origin is from ALB and another origin is from S3 bucket
Based on the path pattern
/images/*/api/*/*
CloudFront - Origin Groups
- to increase high availability and do failover
- Origin Groups: one primary and one secondary origin
- if the primary origin fails, the second one is used (CloudFront will send the same request to the secondary origin)
CloudFront - Field Level Encryption
- protect user sensitive information through application stack
- adds an additional layer of security along with HTTPS
- sensitive information encrypted at the edge close to the user
- uses asymmetric encryption (public private key pair)
- usage
- client send sensitive information to the edge location
- edge location use public key to encrypt the information
- edge location send encrypted information to CloudFront
- CloudFront send information all the way to (CloudFront => ALB => Web Servers) Web server
- Web server uses the private key to decrypt the information
AWS Global Accelerator
Global users for our application
- you have deployed an application and have global users who want to access it directly
- they go over the public internet, which can add a lot of latency due to many hops
- we wish to go as fast as possible through AWS network to minimize latency
Unicast IP vs Anycast IP
- Unicast IP
- one server holds one IP address
- Anycast IP
- all servers hold the same IP address and the client is routed to the nearest one
AWS Global Accelerator
- leverage the AWS internal network to route to your application
- 2 Anycast IP are created for your application
- the Anycast IP send traffic directly to Edge locations
- the edge locations send the traffic to your application (through AWS private network)
Global Accelerator vs CloudFront
-
they both use the AWS global network and its edge locations around the world
-
both services integrate with AWS shield for DDoS protection
-
CloutFront
- improves performance for both cacheable content (images / videos)
- Dynamic content (such as API acceleration and dynamic site delivery)
- content is served at the edge location
-
Global Accelerator
- improves performance for a wide range of applications over TCP or UDP
- proxying packets at the edge to applications running in one or more AWS regions
- good fit for non-HTTP use cases: such as gaming (UDP), IoT (MQTT) or Voice Over IP
- good for HTTP use cases that require static IP (if use Route 53 Geo location, client browser will cache the IP address and redirect user to the old IP for a TTL)
- good for HTTP use cases that require deterministic, fast regional failover
AWS Snow Family
- Highly-secure, portable devices to collect and process data at the edge, and migrate data into and out of AWS
Snowball Edge (for data transfers)
- physical data transport solution
- alternative to moving data over the network
- pay per data transfer job
- provide block storage and Amazon S3 compatible object storage
- Snowball Edge Storage Optimzied
- Snowball Edge Compute Optimized
Snowcore
- small, portable computing, anywhere, rugged and secure, withstands harsh environements
- light, 2.1 kg
- device used for edge computing, storage, and data transfer
- 8 TB usable storage
- must provide your own battery and cables
- can be sent back to AWS offline, or connect it to internet and use AWS datasync to send data
Snowmobile
- transfer exabytes of data (1 EB = 1000 PB = 1,000,000 TB)
- each snowmobile has 100 PB of capacity
- high security
- better than snowball if you transfer more then 10 PB
Edge computing
- process data while its being created on an edge location
- A truck on the road, a ship on the sea, a mining station underground (no internet access)
- these locations may have
- limited / no internet access
- limited / no easy access to computing power
- we setup a snowball / snowcone device to do edge computing
- eventually we can ship back the device to AWS
AWS OpsHub
- Historically, to use Snow Family devices, you need a CLI
- today, you can use AWS OpsHub (a software you install on your computer / laptop) to manage your snow family devices
- unlocking and configuring single or clustered devices
- transferring files
- launching and managing instances running on Snow family devices
- monitor device metrics (storage capacity, active instances)
- launch compatible AWS services on your devices
Snowball into Glacier
- Snowball cannot import to Glacier directly
- you must use Amazon S3 first, in combination with an S3 lifecycle policy
AWS Storage Gateway
- Bridge between on-premises data and cloud data in S3
- use cases: disaster recovery, backup and restore, tiered storage
File Gateway
- configured S3 buckets are accessible using the NFS and SMB protocol
- supports S3 standard, S3 IA, S3 One Zone IA
- bucket access using IAM roles for each File Gateway
- most recently used ata is cached in the file Gateway
- can be mounted on many servers
- integrated with AD (Active Directory) for user authentication
- On-premises server communicate with File Gateway (optionally with Authentication)
- File Gateway communicate with S3 buckets
Volume Gateway
- block storage using iSCSI protocol backed by S3
- backed by EBS snapshot which can help restore on-premises volumes
- cached volumes: low latency access to most recent data
- stored volumes: entire dataset is on premises, scheduled backups to S3
- On-premises server communicate with Volume Gateway using iSCSI protocol
- Volume Gateway communicate with S3 bucket to create EBS snapshots
- Volume Gateway is often used as data backup
Tape Gateway
- some companies have backup processes using physical tapes
- with tape gateway, companies use the same processes but, in the cloud
- Virtual Tape Library (VTL) backed by Amazon S3 and Glacier
- backup data using existing tape-based processes
Storage Gateway - Hardware appliance
- if you don’t have on-premises virtual server, you can buy from Amazon
AWS FSx
AWS FSx for Windows
- EFS is a shared POSIX system for Linux system
- FSx is a fully managed Windows file system share drive
- supports SMB protocol and Windows NTFS
- Microsoft Active Directory integration, ACLs, user quotas
- can be accessed from your on-premises infrastructure
- can be configured to be Multi-AZ
- data is backed up daily to S3
Amazon FSx for Lustre
- Lustre is a type of parallel distributed file system, for large scale computing
- the name Lustre is derived from Linux and Cluster
- Machine Learning, High Performance Computing
- Video processing, Financial Modeling and Electronic Design Automation
- Seamless integration with S3
- can be used from on-premises servers
FSx File System Deployment Options
- Scratch file system
- temporary storage
- data is not replicated
- high burst
- usage: short-term processing, optimize costs
- Persistent File System
- long-term storage
- data is replicated within same AZ
- replace failed files within minutes
- usage: long-term processing, sensitive data
AWS Transfer Family
- a fully managed service for file transfers into and out of Amazon S3 or Amazon EFS using the FTP protocol
- supported protocols
- AWS Transfer for FTP (File Transfer Protocol)
- AWS Transfer for FTPS (File Transfer Protocol over SSL)
- AWS Transfer for SFTP (Secure File Transfer Protocol)
- Managed infrastructure, scalable, reliable, highly available
- pay per provisioned endpoint per hour + data transfers in GB
- store and manage users’ credentials within the services
- integrate with existing authentication systems (Microsoft Active Directory, LDAP, Okta…)
AWS Storage Comparison
- S3: Object Storage
- S3 is going to be an object storage, it’s going to be serverless, you don’t have to prove incapacity ahead of time. It has some deep integration with so many database services.
- Glacier: Object Archival
- Glacier is going to be for object archival. So this is when we want to store objects for a long period of time. Retrieve it very very rarely, and when we retrieve these objects, they’re going to be taking a lot of time to get back to us because they are archived.
- EFS: Network File System for Linux instances, POSIX file system
- EFS is Elastic File System, and this is a network file system for Linux instances. It is a POSIX file system so that means for Linux again. And it is accessible from all your EC2 instances at once. So it is something that is going to be shared and across AZ.
- FSx for Windows: Network File System for Windows servers
- FSx for Windows is the same thing as EFS, but for Windows. So it’s a network file system for your Windows servers.
- FSx for Lustre: High performance computing Linux file system
- FSx for Lustre is Linux and cluster, so it’s for High Performance Computing Linux file system. This is where you’re going to do your HPC running. You only have insanely high IOPS, insanely big capacity. And it has integration with S3 in the back end.
- EBS volume: network storage for one EC2 instance at a time
- EBS volumes is your network storage for one EC2 instance at a time only. And it is bound to a specific availability zone that you create it in. And in case you wanted to change the AZ, you will need to create a snapshot, move that snapshot over, and create a volume from it.
- Instance Storage: physical storage for your EC2 instance (high IOPS)
- Instance Storage is going to be physical storage for your EC2 instance. And so, because it’s attached from the hardware, then it’s going to have a much higher IOPS than EBS. EBS volumes, as we remember, it is up to 16,000 IOPS or 64,000 IOPS for io1. But for Instance Storage, because it is physically attached to your EC2 instance, you can get, for some, millions of IOPS. Um, it’s going to be very high. But the risk is that if your EC2 instance goes down, then you will lose that storage permanently.
- Storage Gateway: file gateway, volume gateway, tape gateway
- Storage Gateway is going to be transporting files from on premise to AWS. So we have File Gateway, Volume Gateway for cache and stored, and Tape Gateway. Each with their use cases.
- Snowball / Snowmobile: to move large amount of data to the cloud, physically
- And then finally, Snowball/Snowmobile to move large amount of data to the cloud physically into S3.
- database: for specific workloads, usually with indexing and querying
Amazon SQS (Simple Queuing Service)
- Fully managed service, used to decouple applications
- attributes
- unlimited throughput, unlimited number of messages in queue
- default retention of messages: 4 days, to maximum 14 days
- low latency
- limitation of 256KB per message sent
- can have duplicate messages (at least once delivery, occasionally)
- can have out of order message (best effort ordering)
Producing Messages
- Produced to SQS using the SDK (SendMessage API)
- the message is persisted in SQS until a concumer deletes it
Consuming Messages
- consumers (running on EC2 instances, servers, or AWS lambda)
- Poll SQS for messages (receive up to 10 message at a time)
- process the messages (example: insert the message into an RDS database)
- delete the messages using the DeleteMessage API
Multiple EC2 instances consumers
- consumers receive and process messages in parallel
- at least once delivery (another consumer will receive the message if the first consumer didn’t process it fast enough)
- best-effort message ordering
- consumers delete messages after processing them
- we can scale consumers horizontally to improve throughput of processing
SQS with Auto Scaling Group
- CloudWatch is monitoring the SQS length
- if SQS length is too long, CloudWatch will trigger an alarm
- Auto Scaling group will increase the number of EC2 instances if the alarm is triggered
SQS Security
- encryption
- in flight encryption using HTTPS API
- at rest encryption using KMS keys
- client side encryption if the client wants to perform encryption / decryption itself
- Access control: IAM policies to regulate access to the SQS API
- SQS access policies (similar to S3 bucket policies)
SQS Queue Access Policy
- Cross Account Access
- if other accounts want to poll message from the SQS queue, we could add policy to the SQS specify which account and allow it to call receiveMessage API
- publish S3 event notifications to SQS queue
- we upload an object to a S3 bucket
- S3 bucket triggered an event message to be sent to SQS queue
- we need to add a policy to SQS queue allowing the bucket to call SendMessage API to the queue
SQS - Message Visibility Timeout
-
after a message is polled by a consumer, it becomes invisible to other consumers
-
by default, the message visibility timeout is 30 seconds
-
that means the message has 30 seconds to be processed and deleted from the queue
-
after the message visibility timeout is over, the message is visible in SQS for other consumers to receive
-
if a message is not processed within the visiblity timeout, it will be processed again by other consumers
-
a consumer could call the ChangeMessageVisibility API to get more time
-
if visibility timeout is high (hours), and consumer crashes, re-processing will take time
-
if visibility timeout is too low (seconds), we may get duplicates
SQS - Dead Letter Queue
- if a consumer fails to process a message within the visibility timeout, the message goes back to the queue
- we can set a threshold of how many times a message can go back to the queue
- after the MaximumReceives threshold is exceeded, the message goes into a dead letter queue (DLQ)
- useful for debugging
- make sure to process the messages in the DLQ before they expire
- good to set a retention of 14 days in the DLQ
SQS - Request - Response Systems
- producer send request with the reply-to queue ID to the Request queue
- responders receive the request from the Request queue and process it
- after processing, responders send the response to the corrent Response queue using the queue ID in the request
- to implement this pattern: use the SQS Temporary Queue Client
- it leverages virtual queues instead of creating / deleting SQS queues (cost effective)
SQS - Delay Queue
- delay a message (consumers don’t see it immediately) up to 15 minutes
- default is 0 seconds (message is avaialble right away)
- can set a default at queue level
- can override the default on send using the DelaySeconds parameter
SQS - FIFO queue
- Frist In First Out
- limited throughput
- exactly once send capability (by removing duplicates), the message that failed to be processed will be insert at the end of the queue
- messages are processed in order by the consumer
Amazon SNS
- the event producer only sends message to one SNS topic
- as many event receivers (subscriptions) as we want to listen to the SNS topic notifications
- each subscriber to the topic will get all the messages (note: new feature to filter messages)
- subscribers can be
- SQS
- HTTP / HTTPS
- lambda
- Emails
- SMS messages
- Mobile notifications
SNS integrates with a lot of AWS services
- many AWS services can send data directly to SNS for notifications
- CloudWatch (for alarms)
- Auto Scaling Groups notifications
- Amazon S3 (on bucket events)
- CloudFormation (upon state changes => failed to build etc…)
- etc…
How to publish
- topic publish (using SDK)
- create a topic
- create a subscription
- publish to the topic
- direct publish (for mobile apps SDK)
- create a platform application
- create a platform endpoint
- publish to the platform endpoint
- works with Google GCM, Apple APNS, Amazon ADM…
Security
- Encryption
- in flight encryption using HTTPS / API
- at rest encryption using KMS keys
- Client side encryption if the client wants to perform encryption / decryption itself
- Access Control: IAM policies to regulate access to the SNS API
- SNS access policies (similar to S3 bucket policies)
- useful for cross account access to SNS topics
- useful for allowing other services (S3…) to write to an SNS topic
SNS + SQS: Fan Out
- Push once in SNS, receive in all SQS queues that are subscribers
- fully decoupled, no data loss
- SQS allows for: data persistence, delayed processing and retries of work
- ability to add more SQS subscribers over time
- make sure your SQS queue access policy allows for SNS to write
e.g. S3 Events to multiple queues or lambda functions
- if you want to send the same S3 event to many SQS queues, or optionally lambda functions, use fan out pattern
SNS FIFO topic
- similar features as SQS FIFO
- ordering by message group ID (all messages in the same group are ordered)
- deduplication using a deduplication ID or Content Based Deduplication
- can only have SQS FIFO queue as subscribers
- limited throughput (same throughput as SQS FIFO)
Message Filtering
- JSON policy used to filter messages sent to SNS topic’s subscriptions
- if a subscription doesn’t have a filter policy, it receives every message
AWS Kinesis
- make it easy to collect, process and analyze streaming data in real time
- ingest real time data such as application logs, Metrics, website clickstreams, IoT telemetry data…
Kinesis Data Streams
- billing is per shard provisioned, can have as many shards as you want
- retention between 1 day (default) to 365 days
- ability to reprocess (replay) data
- once data is inserted in Kinesis, it can’t be deleted (immutability)
- data that shares the same partition goes to the same shard (ordering)
- producers: AWS SDK, Kinesis Producer Library (KPL), Kinesis Agent
- consumers:
- write your own: Kinesis Client Library (KCL), AWS SDK
- managed: AWS Lambda, Kinesis Data Firehose, Kinesis Data Analytics
Kinesis Firehose
- fully managed service, no administration, automatic scaling, serverless
- AWS redshift / Amazon S3 / ElasticSearch
- pay for data going through firehose
- near real time
- 60 seconds latency minimum for non full batches
- or minimum 32 MB of data at a time
- supports many data formats, conversions, transformations, compression
- supports custom data transformations, using AWS Lambda
- can send failed or all data to a backup S3 bucket
| Kinesis Data Streams | Kinesis Data Firehos |
|---|---|
| Streaming service for ingest at scale | load streaming data into S3 / redshift / ES / Thrid party / custom HTTP |
| write custom code (producer, consumer) | fully managed |
| real time (~200ms) | near real time (buffer time min 60 seconds) |
| manage scaling (shard splitting / merging) | automatic scaling |
| data storage for 1 to 365 days | no data storage |
| support replay capability | doesn’t support replay capability |
Kinesis Data Analytics (SQL application)
- perform real time analytics on Kinesis Streams using SQL
- fully managed, no servers to provision
- automatic scaling
- real time analytics
- pay for actual consumtion rate
- can create streams out of the real time queries
- use cases
- time series analytics
- real time dashboards
- real time metrics
Kinesis vs SQS ordering
- let’s assume we have 100 trucks, 5 Kinesis shards, 1 SQS FIFO
- Kinesis data streams
- on average you will have 20 trucks per shard
- trucks will have their data ordered within each shard
- the maximum amount of consumer in parallel we can have is 5
- can receive up to 5MB/s of data
- SQS FIFO
- you only have one SQS FIFO queue
- you will have 100 group ID
- you can have up to 100 consumers (due to the 100 group ID)
- you have up to 300 messages per second (or 3000 if using batching)
- better to use if you have a dynamic number of consumers
| SQS | SNS | Kinesis |
|---|---|---|
| consumer pull data | push data to many subscribers | standard: pull data (2MB per shard), enhanced-fan out: push data (2MB per shard per consumer) |
| data is deleted after being consumed | data is not persisted (lost if not delivered) | possibility to replay data |
| can have as many workers as we want | up to 12,500,000 subscribers | - |
| no need to provision throughput | no need to provision throughput | must provision throughput |
| ordering guearantees only on FIFO queues | FIFO capability for SQS FIFO | ordering at shard level |
| individual message delay capability | integrates with SQS for fan out architecture pattern | data expires after X days |
| - | - | meant for real time big data analytics and ETL |
Amazon MQ
- SQS, SNS are cloud native serviecs, and they are using proprietary protocols from AWS
- traditional applications running from on-premises may use open protocols such as MQTT, AMQP, STOMP, OpenWire, WSS
- when migrating to the cloud, instead of re-engineering the application to use SQS, SNS, we can use Amazon MQ
Container
Docker
- Docker is a software development platform to deploy apps
- apps are packaged in containers that can be run on any OS
- apps run the same, regardless of where they are run
- any machine
- no compatibility issues
- predictable behavior
- less work
- easier to maintain and deploy
- works with any language, any OS, any techonology
Where are Docker images stored
- Docker images are stored in Docker repositories
- public: Docker hub: https://hub.docker.com/
- private: Amazon ECR (Elastic Container Registry)
- Public: Amazon ECR public
Docker Containers Management
- to manage containers, we need a container managemenet platform
- ECS (Amazon’s own container platform)
- Fargate: Amazon’s own serverless container platform
- EKS: Amazon’s managed Kubernetes (open source)
ECS (Elastic Container Service)
- Launch Docker containers on AWS
- you must provision and maintain the infrastructrue (the EC2 instance)
- AWS takes care of starting and stopping the containers
- has integrations with the Application Load Balancer
- ECS agent will be installed on the EC2 instances for ECS to know who to manage
Fargate
- launch Docker containers on AWS
- you do not provision the infrastructure (no EC2 instances to manage)
- serverless offering
- AWS just runs containers for you based on the CPU / RAM you need
- for each container in Fargate it needs an ENI for the public to access it
IAM roles for ECS tasks
- EC2 instance profile
- used by the ECS agent
- makes API calls to ECS service
- send container logs to CloudWatch logs
- pull docker image from ECR
- reference sensitive data in Secret Manager or SSM Parameter store
- ECS task role
- allow each task to have a specific role
- use different roles for the different ECS services you run
- task role is defined in the task definition
ECS data volumes - EFS file systems
- works for both EC2 tasks and Fargate tasks
- ability to mount EFS volumes onto tasks
- tasks launched in any AZ will be able to share the same data in the EFS volume
- Fargate + EFS = serverless + data storage without managing servers
- use case: persistent multi-AZ shared storage for your containers
Load Balancing for EC2 Launch type
- we get a dynamic port mapping
- the ALB supports finding the right port on your EC2 instances
- you must allow on the EC2 instnace’s security group any port from the ALB security group
Load Balancing for Fargate
- each task has a unique IP (because of ENI)
- you must allow on the ENI’s security group the task port from the ALB security group
Event Bridge
- user upload object to S3
- S3 triggers event to Amazon Event Bridge
- Event Bridge triggers the container task to run
- the task will have the role to access S3 and DynamoDB
- task will get the object from S3 and save it to DynamoDB
ECS Rolling updates
- when updating from v1 to v2, we can control how many tasks can be started and stopped, and in which order, by specifying the minimum and maximum healthy percent
ECR (Elastic Container Registry)
- store, manage and deploy containers on AWS, pay for what you use
- fully integrated with ECS and IAM for security, backed by Amazon S3
- supports image vulnerability scanning, version, tag, image lifecycle
- but if we wanted to automate the whole process, we could be using a CICD, so Continuous Integration Continuous Deployment platform and for example, CodeBuild could help us with this to automate building a Docker image and then pushing it onto Amazon ECR to finally trigger an ECS update.
EKS (Elastic Kubernetes Service)
- it is a way to launch managed Kubernetes clusters on AWS
- Kubernetes is an open source system for automatic deployment, scaling and management of containerized application
- it is an alternative to ECS, similar goal but different API
- EKS supports
- EC2 if you want to deploy worker nodes
- Fargate to deploy serverless containers
- use case: if your company is already using Kunernetes on-premises or in another cloud, and wants to migrate to AWS using Kubernetes
- Kubernetes is cloud agnostic (can be used in any cloud, Azure, GCP…)
Serverless
- serverless is a new paradigm in which the developers don’t have to manage servers anymore
- Serverless was pioneered by AWS lambda but now also includes anything that’s managed: database, messaging, storage
- serverless does not mean there are no servers, it means that you just don’t need to manage / provision / see them
Lambda
- easy pricing
- pay per request and compute time
- integrated with the whole AWS suite of services
- integrated with many programming languages
- Node.js
- Python
- Java
- C# (.NET Core)
- Golang
- C# / Powershell
- Ruby
- Lambda container image
- the container image must implement the lambda runtime API
- ECS / Fargate is perferred for running arbitrary Docker images
- easy monitoring through AWS CloudWatch
- easy to get more resources per functions
Lambda Limits
- Execution
- Memory allocation: 128MB - 10GB (64 MB increments)
- Maximum execution time: 15 minutes
- Environment variables (4 KB)
- disk capacity in the function container (in /tmp): 512 MB
- concurrency executions: 1000 (can be increased)
- Deployment
- lambda function deployment size (compressed zip): 50 MB
- size of uncompressed deployment (code + dependencies): 250 MB
- can use the /tmp directory to load other files at startup
- size of environment variables: 4KB
Lambda@Edge
-
you have deployed a CDN using CloudFront
-
what if you wanted to run a global AWS lambda alongside?
-
or how to implement request filtering before reaching your application?
-
for this, you can use Lambda@Edge
- build more responsive applications
- you don’t manage servers, lambda is deployed globally
- customize the CDN content
- pay only for what you use
-
you can use lambda to change CloudFront requests and responses
- after cloudfront receives a request from a viewer (viewer request)
- before cloudfront forwards the request to the origin (origin request)
- after cloudfront receives the response from the origin (origin response)
- before cloudfront forwards the response to the viewer (viewer response)
-
you can also generate responses to viewers without ever sending the request to the origin
DynamoDB
- fully managed, hgihly available with replication across 3 AZ
- NoSQL database, not a relational database
- scales to massive workloads, distributed database
- millions of requests per seconds, trillions of row, 100s of TB of storage
- fast and consistent in performance (low latency on retrieval)
- integrated with IAM for security, authorization and administration
- enables event driven programming with DynamoDB streams
- low cost and auto scaling capabilities
DynamoDB - basics
- DynamoDB is made of tables
- each table has a primary key (must be decided at creation time)
- each table can have an infinite number of items (rows)
- each item has attributes (can be added over time - can be null)
- maximum size of a item is 400KB
- data types supported are
- Scalar Type: string, number, binary, booelan, null
- Document type: list, map
- set types: string set, number set, binary set
Provisioned Throughput
- table must have provisioned read and write capacity units
- read capacity units (RCU), throughput for reads
- 1 RCU = 1 strongly consistent read of 4 KB per second
- 1 RCU = 2 eventually consistent read of 4 KB per second
- write capacity units (WCU), throughput for writes
- 1 WCU = 1 write of 1 KB per second
- option to setup auto scaling of throughput to meet demand
- throughput can be exceeded temporarily using burst credit
- if burst credit are empty, you will get a ProvisionedThroughputExeception
- it is then advised to do an exponential back off retry
DynamoDB - DAX
- DynamoDB accelerator
- seamless cache for DynamoDB, no application re-write
- writes go through DAX to DynamoDB
- micro second latency for cached reads and queries
- solves the Hot Key problem (too many reads)
- 5 minutes TTL for cache by default
- up to 10 nodes in the cluster
- multi AZ (3 nodes minumum recommended for production)
- secure (encryption at rest with KMS, VPC, IAM, CloudTrail…)
DynamoDB Streams
- changes in DynamoDB (create, update, delete) can end up in a DynamoDB stream
- this stream can be read by AWS lambda and we can then do
- react to changes in real time (welcome email to new users)
- analytics
- create derivative tables/ views
- insert into elasticSearch
- cloud implement cross region replication using Streams
- Stream has 24 hours of data retention
Transactions (new from Nov 2018)
- all or nothing type of operations
- coordinated insert, update and delete across multiple tables
- include up to 10 unique items or up to 4MB of data
On Demand (new from Nov 2018)
- no capacity planning needed (WCU / RCU) - scales automatically
- 2.5x more expensive than provisioned capacity
- helpful when spikes are un-predicatable or the application is very low throughput
DynamoDB - Security and other features
- Security
- VPC endpoints available to access DynamoDB without internet
- access fully controlled by IAM
- encryption at rest using KMS
- encryption in transit using SSL / TLS
- backup and restore feature available
- point in time restore like RDS
- no performance impact
- Global Tables (cross region replication)
- multi region, fully replicated, high performance
- active active replication (data will be replicated to other tables no matter which table gets the data first)
- must enable DynamoDB Streams
- useful for low latency, Disater Recovery purposes
- Amazon DMS (Data Migration Service) can be used to migrate to DynamoDB (from Mongo, Oracle, MySQL, S3, etc…)
- you can launch a local DynamoDB on your computer for development purposes
API Gateway
- AWS lambda + API gateway
- support for the webSocket Protocol
- handle API versioning
- handle different environments (dev, test, prod)
- handle security (authentication, authorization)
- create API keys, handle request throttling
- Swagger / Open API import to quickly define APIs
- Transform and validate requests and responses
- generate SDK and API specifications
- cache API responses
API Gateway - Endpoint Types
- Edge Optimized (default): for global clients
- requests are routed through the CloudFront edge locations (improves latency)
- the API gateway still lives in only one region
- Regional
- for clients within the same region
- could manually combine with CloudFront (more control over the caching strategies and the distribution)
- private
- can only by accessed from your VPC using an interface VPC endpoint (ENI)
- use a resource policy to define access
Security
IAM Permissions
- create an IAM policy authorization and attach to User / Role
- API gateway verfies IAM permissions passed by the calling application
- good to provide access within your own infrastructure
- leverage Sig v4 capability where IAM credential are in headers
Lambda authorizer
- users AWS lambda to validate the token in header being passed
- option to cache result of authentication
- helps to use OAuth / SAML / third party type of authentication
- lamdba (authorizer) must return an IAM policy for the user
Cognito User Pools
- cognito fully manages user lifecycle
- API gateway verifies identity automatically from AWS cognito
- no custom implementation required
- Cognito only helps with authentication, not authorization
AWS Cognito
- we want to give our users an identity so that they can interact with our application
AWS Cognito User Pools
- create a serverless database of user for your mobile apps
- simple login: username or email / password combination
- possibility to verify emails / phone numbers and add MFA
- can enable federated identities (Facebook, Google, SAML…)
- sends back a JSON web tokens (JWT)
- can be integrated with API gateway for authentication
AWS Cognito - Federated Identity Pools
- goal
- provide direct access to AWS resources from the client side
- How
- login to federated identity provider - or remain anonymous
- get temporary AWS credentials back from the federated identity pool
- these credentials come with a pre-defined IAM policy stating their permissions
- example
- provide (temporary) access to write to S3 bucket using Facebook login
AWS Cognito Sync
- deprecated - use AWS AppSync now
- store preferneces, configuration, state of app
- cross device synchronization
- offline capability (synchronization when back online)
- requires federated identity pool in Cognito
- store data in datasets
AWS SAM - Serverless Application Model
- framework for developing and deploying serverless applications
- all the configurations is YAML code
- lambda functions
- DynamoDB tables
- API Gateway
- Cognito User Pool
- SAM can help you to run Lambda, API Gateway, DynamoDB locally
- SAM can use CodeDeploy to deploy lambda functions
Databases Comparison
RDS
- managed postgreSQL / MySQL / Oracle / SQL server
- must provision an EC2 instance and EBS volume type and size
- support for read replicas and multi AZ
- security through IAM, security groups, KMS, SSL in transit
- backup / snapshot / point in time restore
- managed and scheduled maintenance
- monitoring through CloudWatch
- use case: store relational datasets (RDBMS / OLTP (online transactional processing)), perform SQL queries, transactional inserts / update / delete is available
Aurora
- compatible API for PostgreSQL / MySQL
- Data is held in 6 replicas, 3 AZ
- auto healing capability
- multi AZ, auto scaling read replicas
- read replicas can be global
- Aurora database can be global for DR or latency purpose
- define EC2 instance type for Aurora instances
- same security / monitoring / maintenance features as RDS
- Aurora Serverless - for unpredicatble / intermittent workloads
- Aurora multi-master - for continuous write failover
- no need to provision
- use case: same as RDS, but with less maintenance / more flexibility / more performance
ElasticCache
- managed Redis / Memcached (similar offering as RDS, but for caches)
- in memory data store, sub-millisecond latency
- must provision an EC2 instance type
- support for Clustering (Redis), and Multi AZ, read replicas (sharding)
- security through IAM, security groups, KMS, Redis Auth
- backup / snapshot / point in time restore
- managed and scheduled maintenance
- monitoring through CloudWatch
- use case: key value store, frequent reads, less writes, cache results for DB queries, store session data for websites, cannot use SQL
DynamoDB
- AWS proprietary technology, managed NoSQL database
- serverless, provisioned capacity, auto scaling, on demand capacity
- can replace ElastiCache as a key value store
- highly available, multi AZ by default, read and writes are decoupled, DAX for read cache
- reads can be eventually consistent (occasional old data) or strongly consistent (always latest data)
- security, authentication and authorization is done through IAM
- DynamoDB Streams to integrate with AWS lambda
- backup and restore feature, global table feature
- monitoring through CloudWatch
- can only query on primay key, sort key, or indexes
- use case: serverless applications development, distributed serverless cache, doesn’t have SQL query language available, has transactions capability from Nov 2018
S3
- great for big objects, not so great for small objects (because of latency)
- serverless, scales infinitely, max object size is 5TB
- strong consistency
- Tiers: S3 standard, S3 IA, S3 One Zone IA, Glacier, for backups
- features: versioning, encryption, cross region replication etc…
- security: IAM, bucket policy, ACL
- encryption: SSE-S3, SSE-KMS, SSE-C, client side encryption, SSL in transit
- use case: static files, key value store for big files, website hosting
Athena
- fully serverless query engine with SQL capabilities
- used to query data in S3
- pay per query
- output results back to S3
- secured through IAM
- use case: one time SQL queries, serverless queries on S3, log analytics
RedShift
-
Redshift is based on PostgreSQL, but it is not used for OLTP
-
its OLAP - online analytical processing (analytics and data warehousing)
-
Columnar storage of data (instead of row based)
-
massively parallel query execution
-
pay as you go based on the instances provisioned
-
has a SQL interface for performing the queries
-
BI tools such as AWS quicksight or Tableau integrate with it
-
data is loaded from S3 / DynamoDB, DMS, other DBs
-
from 1 node to 128 nodes, up to 160 GB of space per node
-
leader node: for query planning, results aggregation
-
compute node: for performing the queries, send results to leader
-
Redshift Spectrum: perform queries directly against S3 (no need to load)
-
backup and restore, security VPC / IAM / KMS, monitoring
-
Redshift enhanced VPC routing: COPY / UNLOAD goes through VPC
Snapshots / DR
- Redshift has no multi AZ mode
- snapshots are point in time backups of a cluster, stored internally in S3
- snapshots are incremental (only what has changed is saved)
- you can restore a snapshot into a new cluster
- automated: every 8 hours, every 5 GB, or on schedule, set retention
- manual: snapshot is retained until you delete it
- you can configure Amazon Redshift to automatically copy snapshots (automated or manual) of a cluster to another AWS region
Redshift Specturm
- query data that is already in S3 without loading it
- must have a Redshift cluster available to start the query
- the query is then submitted to thousands of Redshift Spectrum nodes
- data doesn’t need to be loaded into Redshift first
AWS Glue
- managed extract, transform, and load (ETL) service
- useful to prepare and transform data for analytics
- fully serverless service
Glue Data Catalog
- Glue data catalog: catalog of datasets (metadata)
- S3 => AWS Glue Data Crawler => AWS Glue Data Catalog => Amazon Athena
Neptune
- fully managed graph database
- when do we use graphs?
- high relationship data
- social networking: users friends with users, replied to comment on post of user and likes other comments
- knowledge graphs (Wikipedia)
- highly available across 3 AZ, with up to 15 read replicas
- point in time recovery, continuous backup to Amazon S3
- support for KMS encryption at rest + HTTPS
ElasticSearch
- example: in dynamoDB, you can only find by primary key or indexes
- with ElasticSearch you can search any field, even partially matches
- it is common to use ElasticSearch as a complement to another database
- ElasticSearch also has some usage for Big Data applications
- you can provision a cluster of instances
- built in integrations: Amazon Kinesis data Firehose, SSL and VPC
- comes with Kibana (visulization) and Logstash (log ingestion) - ELK stack
AWS CloudWatch
CloudWatch Metrics
- CloudWatch provides metrics for every servcies in AWS
- Metric is a variable to monitor (CPU Utilization, Network In…)
- metrics belong to namespaces
- dimension is an attribute of a metric (instance id, environment, etc…)
- up to 10 dimensions per metric
- metrics have timestamps
- can create CloudWatch dashboards of metrics
EC2 Detailed monitoring
- EC2 instance metrics have metrics every 5 minutes
- with detailed monitoring (for a cost), you get data every 1 minute
- use detailed monitoring if you want to scale faster for your ASG
- the AWS free tier allows us to have 10 detailed monitoring metrics
- Note: EC2 memory usage is by default not pushed (must be pushed from inside the instance as a custom metric)
CloudWatch Custom Metrics
- possiblity to define and send your own custom metrics to CloudWatch
- example: memory usage, disk space, number of logged in users…
- use API call PutMetricData
- ability to use dimensions (attributes) to segment metrics
- metric resolution (StorageResolution API parameter - two possible values)
- Standard: 1 minute
- high resolution: 1 / 5 / 10 / 30 seconds - higher cost
- important: accepts metric data points two weeks in the past and two hours in the future (make sure to configure your EC2 instance time correctly)
CloudWatch Dashboards
- great way to setup custom dashboards for quick access to key metrics and alarms
- dashboards are global
- dashboards can include graphs from different AWS accounts and regions
- you can change the time zone and time range of the dashboards
- you can setup automatic refresh (10s, 1m, 2m, 5m, 15m)
- dashboards can be shared with people who don’t have an AWS account (public, email address…)
- pricing
- 3 dashboards (up to 50 metrics) for free
- $3 dollar / dashboard / month after
CloudWatch Logs
-
applications can send logs to CloudWatch using the SDK
-
CloudWatch can collect log from
- elastic beanstalk: collection of log from application
- ECS: collection from containers
- AWS lambda: collection from function logs
- VPC flow logs: VPC specific logs
- API Gateway
- CloudTrail based on filter
- CloudWatch log agents: for example on EC2 machines
- Route53: log DNS queries
-
CloudWatch Logs can go to
- batch exporter to S3 for archival
- Stream to ElasticSearch cluster for further analytics
-
Logs storage architecture
- log groups: arbitrary name, usually representing an application
- log stream: instances within application / log files / containers
-
can define log expiration policies (never expire, 30 days, etc…)
-
using the AWS CLI we can tail CloudWatch logs
-
to send logs to CloudWatch, make sure IAM permissions are correct
-
security: encryption of logs using KMS at the group level
CloudWatch Logs for EC2
- by default, no logs from your EC2 machine will go to CloudWatch
- you need to run a CloudWatch agent on EC2 to push the log files you want
- make sure IAM permissions are correct
- the CloudWatch log agent can be setup on-premises too
CloudWatch Logs Agent vs Unified Agent
- CloudWatch Logs Agent
- old version of the agent
- can only send to CloudWatch logs
- CloudWatch unified agent
- collect additional system-level metrics such as RAM, processors,etc…
- collect logs to send to CloudWatch logs
- centralized configuration using SSM Parameter Store
CloudWatch Alarms
- Alarms are used to trigger notifications for any metric
- various options (sampling, percentage, max, min, etc…)
- alarm status
- OK
- INSUFFICIENT_DATA
- ALARM
- period
- length of time in seconds to evaluate the metric
- high resolution custom metrics: 10 / 30 or multiples of 60 seconds
Alarm Targets
- Stop, terminate, reboot or recover an EC2 instance
- trigger auto scaling action
- send notification to SNS (from which you can do pretty much anything)
EC2 instance recovery
- status check
- instance status = check the EC2 VM
- system status = check the underlying hardware
- recovery
- same private, public, elastic IP, metadata, placement group
CloudWatch Alarm: good to know
- alarms can be created based on CloudWatch Logs Metrics Filters
- to test alarms and notifications, set the alarm state to alarm using CLI
CloudWatch Events
- event pattern: intercept events from AWS services (sources)
- example soruces: EC2 instance start, codebuild failure, S3 trsuted advisor
- can intercept any API call with CloudTrail integration
- schedule or Cron (example: create an event every 4 hours)
- A JSON payload is created from the event and passed to a target
- compute: lambda, batch, ECS task
- integration: SQS, SNS, Kinesis data streams, Kinesis data firehose
- Orchestration: step functions, codepipeline, codebuild
- maintenance: SSM, EC2 actions
Amazon EventBridge
-
eventbridge is the next evolution of CloudWatch Events
-
default event bus: generated by AWS services (CloudWatch events)
-
partner event bus: receive events from SaaS service or applications
-
custom event buses: for your own applications
-
event buses can be accessed by other AWS accounts
-
Rules: how to process the events (similar to CloudWatch Events)
-
Amazon EventBridge builds upon and extends CloudWatch events
-
it uses the same service API and endpoint, and the same underlying service infrastructure
-
eventbridge allows extension to add event buses for your custom applications and your thrid party SaaS apps
-
event bridge has the schema registry capability
-
eventbridge has a different name to mark the new capabilities
-
over time, the CloudWatch events name will be replaced with eventbridge
AWS CloudTrail
- provides governance, compliancen and audit for your AWS account
- CloudTrail is enabled by default
- get an history of events / API calls made within your AWS account by
- console
- SDK
- CLI
- AWS Service
- can put logs from CloudTrail into CloudWatch logs or S3
- a trail can be applied to all regions (default) or a single region
- if a resource is deleted in AWS, investigate CloudTrail first
CloudTrail Insights
- enable CloudTrail insights to detect unusual activity in your account
- inaccurate resource provisioning
- hitting service limits
- bursts of AWS IAM actions
- gaps in periodic maintenance activity
- CloudTrail insights analyzes normal management events to create a baseline
- and then continuously analyzes write events to detect unusual patterns
- anomalies appear in the CloudTrail console
- event is sent to Amazon S3
- an eventbridge event is generated (for automation needs)
CloudTrail Events retention
- events are stored for 90 days in CloudTrail
- to keep events beyond this period, log them to S3 and use Athena
AWS Config
- helps with auditing and recording compliance of your AWS resources
- helps record configurations and changes over time
- questions that can be solved by AWS Config
- is there unrestricted SSH access to my security groups
- do my buckets have any public access
- how has my ALB configuration changed over time
- you can receive alerts (SNS notifications) for any changes
- AWS Config is a per-region service
- can be aggregated across regions and accounts
Config Rules - remediations
- automate remediation of non-compliant resources using SSM automation documents
- use AWS-managed automation documents or create custom automation documents
- tip: you can create custom automation documents that invokes lambda function
- you can set remediation retries if the resource is still non-compliant after auto-remediation
Config Rules - notifications
- use eventbridge to trigger notifications when AWS resources are non-compliant
- ability to send configuration changes and compliance state notifications to SNS (all events - use SNS filtering or filter at client-side)
CloudWatch vs CloudTrail vs Config
- CloudWatch
- performance monitoring (metrics, CPU, network, etc…) and dashboards
- event and alerting
- log aggregation and analysis
- CloudTrail
- record API calls made within your account by everyone
- can define trails for specific resources
- global service
- Config
- record configuration changes
- evaluate resources against comliance rules
- get timeline of changes and compliance
Example for an Elastic Load Balancer
- CloudWatch
- monitoring incoming connections metric
- visualize error codes as a percentage over time
- make a dashboard to get an idea of your load balancer performance
- CloudTrail
- track who made any changes to the load balancer with API calls
- Config
- trakc security group rules for the load balancer
- track configuration changes for the load balancer
- ensure an SSL certificate is always assigned to the load balancer (compliance)
AWS STS (Security Token Service)
- allows to grant limited and temporary access to AWS resources
- token is valid for up to one hour (must be refreshed)
- AssumeRole
- within your own account: for enhanced security
- cross account access: assume role in target account for perform actions there
- AssumeRoleWithSAML
- return credentials for users logged with SAML
- AssumeRoleWithWebIdentity
- return credentials for users logged with an IDP (facebook, google…)
- AWS recommends against using this, and using Cognito instead
- GetSessionToken
- for MFA, from a user or AWS account root user
- define an IAM role within your account or cross-account
- define which principals can access this IAM role
- use AWS STS to retrieve credentials and impersonate the IAM role you have access to (AssumeRole API)
- temporary credentials can be valid between 15 minutes to 1 hour
Identity Federation in AWS
- federation lets users outside of AWS to assume temporary role for accessing AWS resources
- these users assume identity provided access role
- federations can have many flavors
- SAML
- Custom Identity Broker
- Amazon Cognito
- Single Sign On
- Non-SAML with AWS Microsoft AD
- using federation, you don’t need to create IAM users (user management is outside of AWS)
SAML 2.0 Federation
- needs to setup a trust between AWS IAM and SAML (both ways)
- SAML enables web based, cross domain SSO
- uses the STS API: AssumeRoleWithSAML
- note federation through SAML is the old way of doing things
- Amazon SSO federation is the new managed and simpler way
AWS Directory Services
- AWS Managed Microsoft AD
- create your own AD in AWS, manage users locally, supports MFA
- establish trust connections with your on-premises AD
- AD Connector
- Directory Gateway (proxy) to redirect to on-premises AD
- users are managed on the on-premises AD (not on AWS)
- Simple AD
- AD compatible managed directory on AWS
- cannot be joined with on-premises AD (users managed on AWS only)
AWS Organizations
- global service
- allows to manage multiple AWS accounts
- the main account is the master account - you can’t change it
- other accounts are member accounts
- member accounts can only be part of one organization
- consolidated billing across all accounts - single payment method
- pricing benefits from aggregated usage
- API is available to automate AWS account creation
Multi account strategies
- create accounts per department, per cost center, per dev/test/prod, based on regulatory restrictions (using SCP), for better resource isolation, to have separate per-account service limits, isolated account for logging
- multi account vs one account multi VPC
- use tagging standards for billing purposes
- enable CloudTrail on all accounts, send logs to central S3 account
- send CloudWatch logs to central logging account
- establish cross account roles for admin purpose
Service Control Policies (SCP)
- whitelist or blacklist IAM actions
- applied at the OU or Account level
- does not apply to the master account
- SCP is applied to all the users and roles of the account, including Root
- the SCP does not affect service linked roles
- service linked roles enable other AWS services to integrate with AWS organizations and can’t be restricted by SCPs
- SCP must have an explicit Allow (does not allow anything by default)
- use cases
- restrict access to certain services (for example: can’t use EMR)
- enforce PCI compliance by explicitly disabling services
AWS Organization - moving accounts
- to migrate accounts from one organization to another
- remove the member account from the old organization
- send an invite to the new organization
- accept the invite to the new organization from the member account
- if you want the master account of the old organization to also join the new organization
- remove the member accounts from the organization using the procedure above
- delete the old organization
- repeat the process above to invite the old master account to the new org
IAM Advanced
IAM for S3
- ListBucket permission applies to
arn:aws:s3:::test- bucket level permission
- GetObject, PutObject, DeleteObject applies to
arn:aws:s3:::test/*- object level permission
IAM Roles vs Resource Based Policies
- when you assume a role (user, application or service), you give up your original permissions and take the permissions assigned to the role
- when using a resource based policy, the principal doesn’t have to give up his permissions
IAM permission boundaries
- IAM permission boundaries are supported for users and roles (not groups)
- advanced feature to use a managed policy to set the maximum permissions an IAM entity can get
- if a user has been assigned a permission boundary so that it can only access S3, then no matter what permission policies it has, it can only access to S3, nothing else.
AWS Resource Access Manager (RAM)
- share AWS resources that you own with other AWS accounts
- share with any account or within your organization
- avoid resource duplication
- VPC subnets
- allow to have all the resources launched in the same subnets
- must be from the same AWS organization
- cannot share security groups and default VPC
- participants can manage their own resources in there
- participants can’t view, modify, delete resources that belong to other participants or the owner
- AWS transit gateway
- route53 resolver rules
- license manager configurations
AWS SSO
- centrally manage single sign on to access multiple accounts and third party business applications
- integrated with AWS organizations
- support SAML 2.0 markup
- integration with on-premises active directory
- centralized permissioin management
- centralized auditing with CloudTrail
AWS Security
Encryption in flight (SSL)
- data is encrypted before sending and decrypted after receiving
- SSL certificate help with encryption (HTTPS)
- encryption in flight ensures no MITM (man in the middle) attach can happen
Server side encryption at rest
- data is encrypted after being received by the server
- data is decrypted before being sent
- it is stored in an encrypted form thanks to a key (usually a data key)
- the encryption / decryption keys must be managed somewhere and the server must have access to it
Client side encryption
- data is encrypted by the client and never decrypted by the server
- data will be decrypted by a receiving client
- the server should not be able to decrypt the data
AWS KMS (key management service)
- anytime you hear encryption for an AWS service, it is most likely KMS
- easy way to control access to your data, AWS manages keys for us
- fully integrated with IAM authorization
- seamlessly integrated into
- EBS
- S3
- Redshift
- RDS
- SSM
- but you can also use the CLI / SDK
KMS - Customer Master Key (CMK) Types
- Symmetric (AES-256)
- first offering of KMS, single encryption key that is used to encrypt and decrypt
- AWS services that are integrated with KMS use Symmetric CMKs
- you never get access to the key unencrypted (must call KMS API to use)
- Asymmetric (RSA and ECC key pairs)
- public (Encrypt) and private (decrypt) key
- used for encrypt / decrypt, or sign / verify operations
- the public key ios downloadable, but you can’t access the private key unencrypted
- use case: encryption outside of AWS by users who can’t call the KMS API
Pricing
- able to fully manage the keys and policies
- create
- rotation policies
- disable
- enable
- able to audit key usage (using CloudTrail)
- 3 types of customer master keys (CMK)
- AWS managed service default CMK: free
- user keys created in KMS: $1 / month
- user keys imported (must be 256-bit symmetric key): $1 / month
- plus pay for API call to KMS
KMS 101
- anytime you need to share sensitive information, use KMS
- database passwords
- credentials to external service
- private key of SSL certificates
- the value in KMS is that the CMK used to encrypt data can never be retrieved by the user, and the CMK can be rotated for extra security
- never ever store your secrets in plaintext, especially in your code
- encrypted secrets can be stored in the code / environment variables
- KMS can only help in encrypting up to 4 KB of data per call
- if data > 4KB, use envelope encryption
KMS key policies
- control access to KMS keys, similar to S3 bucket policies
- different: you cannot control access without them
- default KMS key policy
- created if you don’t provide a specific KMS key policy
- complete access to the key to the root user = entire AWS account
- the root user can administer the key and all IAM accounts can use the key
- gives access to the IAM policies to the KMS key
- custom KMS key policy
- define users, roles that can access the KMS key
- define who can administer the key
- useful for cross-account access of your KMS key
KMS Automatic Key Rotation
- for Costumer managed CMK (not AWS managed CMK)
- if enabled: automatic key rotation heppens every 1 year
- previous key is kept active so you can decrypt old data
- new key has the same CMK ID (only the backing key is changed)
SSM Parameter Store
- secure storage for configuration and secrets
- optional seamless encryption using KMS
- serverless, scalable, durable, easy SDK
- version tracking of configurations / secrets
- configuration management using path and IAM
- notifications with CloudWatch events
- integration with CloudFormation
AWS Secrets Manager
- newer service, meant for storing secrets
- capability to force rotation of secrets every X days
- automate generation of secrets on rotation (uses lambda)
- integration with Amazon RDS
- secrets are encrypted using KMS
CloudHSM
- AWS provisions encryption hardware
- dedicated hardware (HSM = Hardware Security Module)
- you manage your own encryption keys entirely (not AWS)
- HSM device is tamper resistant
- supports both symmetric and asymmetric encryption (SSL/TLS keys)
- no free tier available
- must use the CloudHSM client software
- refshift support CloudHSM for database encryption and key management
- good option to use with SSE-C encryption
AWS Shield
- AWS shield standard
- free service that is activated for every AWS customer
- provides protection from attacks such as SYN/UDP floods, reflection attacks and other layer 3 / layer 4 attacks
- AWS Shield Advanced
- optional DDoS mitigation service ($3000 per month per organization)
- protect against more sophisticated attack on EC2, ELB, CloudFront, Global Accelerator, Route53
AWS WAF (Web Application Firewall)
- protects your web applications from common web exploits (layer 7)
- layer 7 is HTTP (vs layer 4 is TCP)
- deploy on Application Load Balancer, API Gateway, CloudFront
- define web ACL
- rules can include: IP addresses, HTTP headers, HTTP body, URI strings
- protects from common attack - SQL injection and cross-site scripting (XSS)
- size constraints, geo-match
- rate based rules (to count occurrences of events) - for DDoS protection
AWS GuardDuty
- intelligent threat discovery to protect AWS account
- uses machine learning algorithms, anomaly detection, third party data
- one click to enable (30 days trial), no need to install software
- input data includes
- CloudTrail log: unusual API calls, unauthorized deployments
- VPC flow logs: unusual internal traffic, unusual IP addresses
- DNS logs: compromised EC2 instances sending encoded data within DNS queries
- can setup CloudWatch event rules to be notified in case of findings
- CloudWatch events rules can target AWS lambda or SNS
- can protect against CryptoCurrency attacks
AWS Inspector
- automated security assessments for EC2 instances
- analyze the running OS against known vulnerabilities
- analyze against unintended network accessibility
- AWS Inspector agent must be installed on OS in EC2 instances
- after the assessment, you get a report with a list of vulnerabilities
- possibilitiy to send notifications to SNS
AWS Macie
- Amazon Macie is a fully managed data security and data privacy service that uses machine learning and pattern matching to discover and protect your sensitive data in AWS
- Macie helps identify and alert you to sensitive data, such as personally identifiable information (PII)
AWS VPC
Understanding CIDR (Classless Inter-Domain Routing) - IPv4
-
CIDR are used for security groups rules, or AWS networking in general
-
they help to define an IP address range
-
a CIDR has two components
- the base IP
- the subnet mask
-
the base IP represents an IP contained in the range
-
the subnet masks defines how many bits can change in the IP
-
the subnet masks basically allows part of the underlying IP to get additional next values from the base IP
/32allow for 1 IP =2^0/31allow for 1 IP =2^1/30allow for 1 IP =2^2/29allow for 1 IP =2^3/28allow for 1 IP =2^4/27allow for 1 IP =2^5/26allow for 1 IP =2^6/25allow for 1 IP =2^7/24allow for 1 IP =2^8/16allow for 1 IP =2^16/0allow for 1 IP =2^32
-
quick memo
/32- no IP number can change/24- last IP number can change/16- last IP two numbers can change/8- last IP 3 numbers can change/0- all IP numbers can change
Private vs public IP allowed ranges
- the internet assigned number authority established certain blocks of IPv4 addresses for the use of private (LAN) and public addresses
- private IP can only allow certain values
- 10.0.0.0 - 10.255.255.255 (in big networks)
- 172.16.0.0 - 172.31.255.255 (default AWS one)
- 192.168.0.0 - 192.168.255.255 (home networks)
- all the rest of the IP on the internet are public IP
Default VPC walkthrough
- all new accounts have a default VPC
- new instances are launched into default VPC if no subnet is specified
- default VPC have internet connectivity and all instances have public IP
- we also get a public and private DNS name
VPC in AWS - IPv4
- you can have multiple VPCs in a region (max 5 per region)
- max CIDR per VPC is 5, for each CIDR
- min size is
/28= 16 IP addresses - max size is
/16= 65536 IP addresses
- min size is
- because VPC is private, only the private IP ranges are allowed
- your VPC CIDR should not overlap with your other networks
Subnets - IPv4
- AWS reserves 5 IPs addresses (first 4 and last 1 IP address) in each subnet
- these 5 IPs are not available for use and cannot be assigned to an instance
- if CIDR block is 10.0.0.0/24, reserved IP are
- 10.0.0.1: network address
- 10.0.0.2: reserved by AWS for the VPC router
- 10.0.0.3: reserved by AWS for mapping to Amazon provided DNS
- 10.0.0.4: reserved by AWS for future use
- 10.0.0.255: network broadcast address, AWS does not support broadcast in a VPC, therefore the address is reserved
- exam tip
- if you need 29 IP addresses for EC2 instances, you can’t choose a subnet of size /27 (32 IPs)
- you need at least 64 IP, subnet size /26 (
64 - 5 > 29, but32 - 5 <= 29)
Internet Gateways
- internet gateways helps our VPC instances connect with the internet
- it scales horizontally and is HA and redundant
- must be created separately from VPC
- one VPC can only be attached to one IGW and vice versa
- internet gateway is also a NAT for the instances that have a public IPv4
- internet gateways on their own do not allow internet access
- route tables must also be edited
If you launch an EC2 instance, to give the instance public internet, you need to edit the route table.
- associate route table to the subnet
- add a rule in route table, so that when instance is trying to access a public IP, it will route the traffic to the internet gateway
For instances in private subnet, if they were to access it through the internet gateway, they would also be accessible from the internet (not we want). So we need NAT
NAT instances - network address translation
- allows instances in the private subnets to connect to the internet
- must be launched in a public subnet
- must disable EC2 flag: source / destination check
- must have elastic IP attached to it
- route table must be configured to route traffic from private subnets to NAT instance
NAT instance will then route traffic to the internet gateway because of the route table rules.
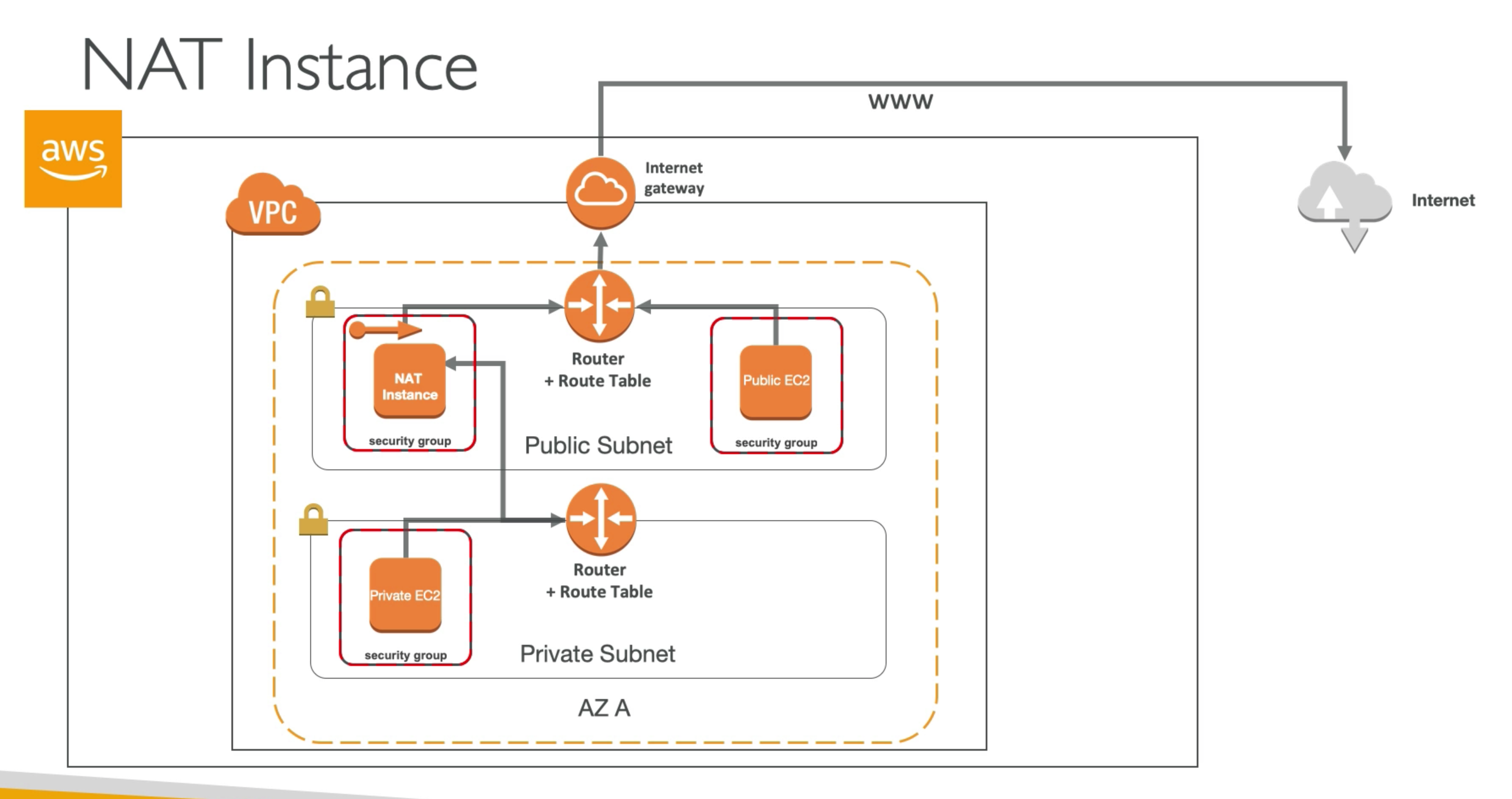
NAT Gateway
- AWS managed NAT, higher bandwidth, better availability, no admin needed
- pay by the hour for usage and bandwidth
- NAT is created in a specified AZ, uses an EIP
- cannot be used by an instance in the subnet (only from the other subnets)
- requires an IGW (private subnet -> NAT -> IGW)
- no security group to manage / required
NAT Gateway with HA
- NAT gateway is resilient within a single AZ
- must create multiple NAT gateway in multiple AZ for fault-tolerance
- there is no cross AZ failover needed because if an AZ goes down it doesn’t need NAT
DNS Resolution in VPC
- enableDnsSupport (DNS Resolution settings)
- default is True
- helps decide if DNS resolution is supported for the VPC
- if True, queries the AWS DNS server at 169.254.169.253
- enableDnsHostname (DNS Hostname setting)
- False by default for newly created VPC
- True by default for default VPC
- won’t do anything unless enableDnsSupport is True
- if True, assign public hostname to EC2 instance if it has a public
- if you use custom DNS domain names in a private zone in Route 53, you must set both these attributes to true
Network ACLs and Security Group
-
Security group is the firewall of EC2 Instances.
-
Network ACL is the firewall of the VPC Subnets.
-
Security groups are tied to an instance whereas Network ACLs are tied to the subnet.
-
Network ACLs are applicable at the subnet level, so any instance in the subnet with an associated NACL will follow rules of NACL. That’s not the case with security groups, security groups has to be assigned explicitly to the instance.
-
This means any instances within the subnet group gets the rule applied. With Security group, you have to manually assign a security group to the instances.
-
Security groups are stateful: This means any changes applied to an incoming rule will be automatically applied to the outgoing rule. e.g. If you allow an incoming port 80, the outgoing port 80 will be automatically opened.
-
Network ACLs are stateless: This means any changes applied to an incoming rule will not be applied to the outgoing rule. e.g. If you allow an incoming port 80, you would also need to apply the rule for outgoing traffic.
Rules: Allow or Deny
- Security group support allow rules only (by default all rules are denied). e.g. You cannot deny a certain IP address from establishing a connection.
- Network ACL support allow and deny rules. By deny rules, you could explicitly deny a certain IP address to establish a connection example: Block IP address 123.201.57.39 from establishing a connection to an EC2 Instance.
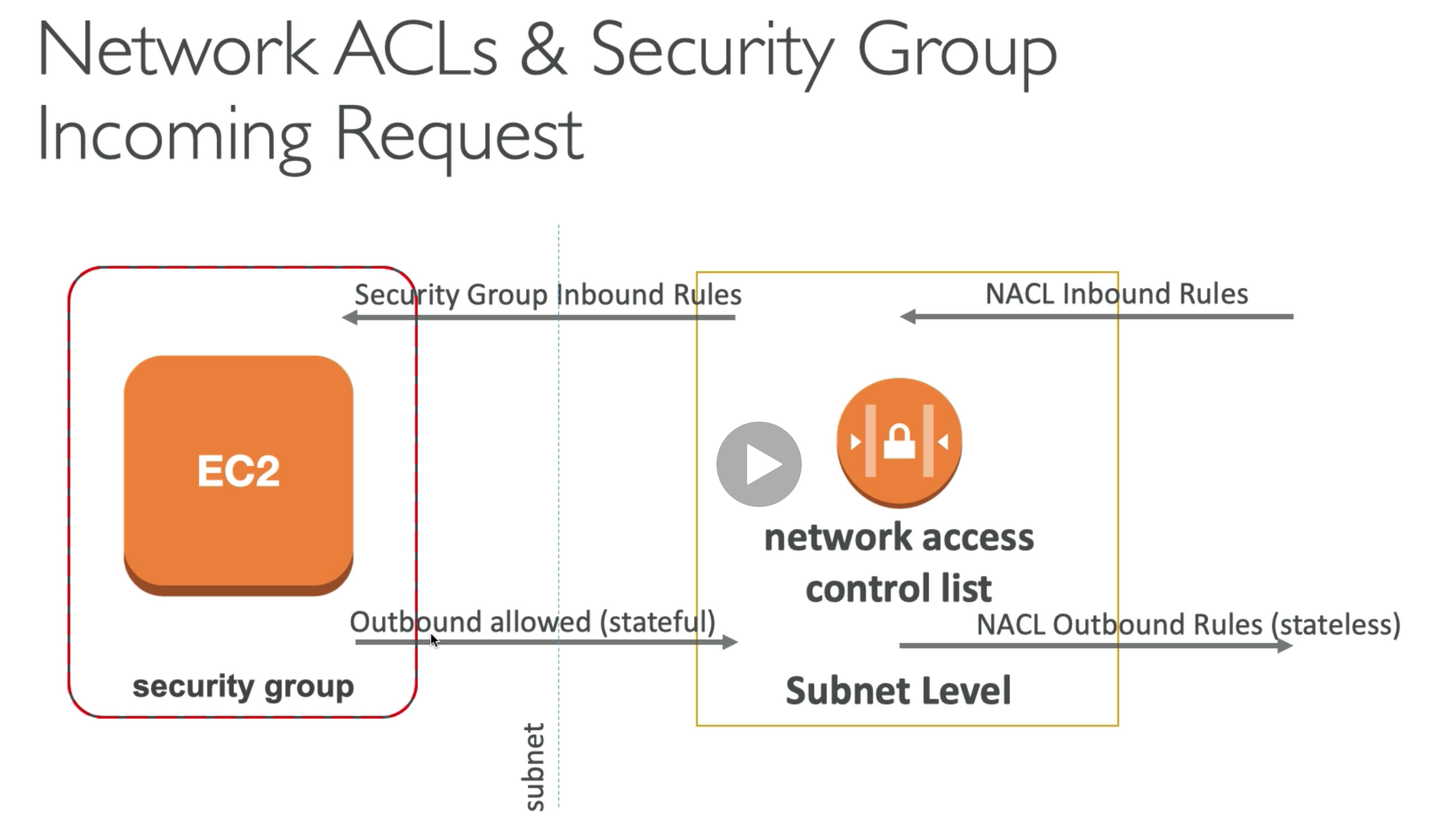
| Security Group | Network ACL |
|---|---|
| Operates at the instance level | Operates at the subnet level |
| supports allow rules only | supports allow rules and deny rules |
| is stateful: return traffic is automatically allowed, regardless of any rules | is stateless: return traffic must be explicity allowed by rules |
| we evaluate all rules before deciding whether to allow traffic | we proces rules in number order when deciding whether to allow traffic |
| applies to an instance only if someone specifies the security group when launching the instance, or associates the security group with the instance later on | automatically applies to all instances in the subnets it’s associated with (therefore, you don’t have to rely on users to specify the security group) |
VPC Peering
- connect 2 VPCs, privately using AWS network
- make them behave as if they were in the same network
- must not have overlapping CIDR
- VPC peering connection is not transitive (must be established for each VPC that need to communicate with one another)
e.g. if we connect VPC A to VPC B and also connect VPC B to VPC C, this doesn’t mean VPC A is connected to VPC C. - you can do VPC peering with another AWS account
- you must update route tables in each VPC’s subnets to ensure instances can communicate
VPC Peering - good to know
- VPC peering can work inter region, cross account
- you can reference a security group of a peered VPC (work cross account)
VPC Endpoint
- endpoints allow you to connect to AWS services using a private network instead of the public www network
- they scale horizontally and are redundant
- they remove the need of IGW, NAT, etc… to access AWS services
- interface
- provisions an ENI (private IP address) as an entry point (must attach security group) - most AWS services
- gateway
- provisions a target and must be used in a route table - S3 and DynamoDB
Flow Logs
- capture information about IP traffic going into your interfaces
- VPC flow logs (includes the other two)
- subnet flow logs
- elastic network interface flow logs
- helps to monitor and troubleshoot connectivity issues
- flow logs data can go to S3 / CloudWatch Logs
- captures network information from AWS managed interfaces too: ELB, RDS, ElastiCache, Redshift, WorkSpaces
Bastion Hosts
- we can use a Bastion Host to SSH into our private instances
- the bastion is in the public subnet which is then connected to all other private subnets
- Bastion Host security group must be tightened
- exam tip: make sure the bastion host only has port 22 traffic from the IP you need. not from the security groups of your other instances
Site to Site VPN
- Virtual Private Gateway
- VPN concentrator on the AWS side of the VPN connection
- VGW (VPC Gateway) is created and attached to the VPC from which you want to create the Site-to-Site VPN connection
- Customer Gateway
- software application or physical device on customer side of the VPN connection
- ip address
- use static, internet-routable IP address for your customer gateway device
- if behind a CGW (Cloud Gateway) behind a NAT, use the public IP address of the NAT
Direct Connect (DX)
- provides a dedicated private connection from a remote network to your VPC
- dedicated connection must be setup between your data center and AWS direct connect locations
- you need to setup a Virtual Private Gateway on your VPC
- access public resources (S3), and private (EC2) on same connection
- use cases
- increase bandwidth throughput: working with large data sets - lower cost
- more consistent network experience - applications using real time data feeds
- hybrid environments (on premises + cloud)
- supports both IPv4 and IPv6
Direct connect gateway
- if you want to setup a direct connect to one or more VPC in many different regions (same account), you must use a direct connect gateway
Connection types
- dedicated connections
- 1 Gbps and 10 Gbps capacity
- physical ethernet port dedicated to a customer
- request made to AWS first, then completed by AWS direct connetion partners
- hosted connections
- 50 Mbps, 500 Mbps to 10 Gbps
- connection requests are made via AWS direct connect partners
- capacity can be added or removed on demand
- 1,2,5,10 Gbps available at select AWS direct connect partners
- lead times are often longer than 1 month to establish a new connection
Encryption
- data in transit is not encrypted but is private
- AWS direct connect + VPN provides an IPsec-encrypted private connection
- good for an extra level of security, but slightly more complex to put in place
Resiliency
- High resiliency for critical workloads
- one connection at multiple locations
- maximum resiliency for critical workloads
- maximum resilience is achieved by separate connections
- terminating on separate devices in more than one location
Egress (outgoing) only internet gateway
- Egress only internet gateway is for IPv6 only
- similar function as a NAT, but a NAT is for IPv4
- good to know: IPv6 are all public addresses
- therefore all our instances with IPv6 are publicly accessible
- Egress only internet gateway gives our IPv6 instances access to the internet, but they won’t be directly reachable by the internet
- after creating an Egress only internet gateway, edit the route tables
AWS Private Link - VPC Endpoint Service
How to expose services in your VPC to other VPCs?
- Option1: make it public
- goes through the public www
- tough to manage access
- Option2: VPC peering
- must create many peering relations (peering relation is one-to-one)
- opens the whole network(maybe you just want one of your services to be exposed, not the whole VPC)
AWS Private Link
- most secure and scalable way to expose a service to 1000s of VPCs
- does not require VPC peering, internet gateway, NAT, route tables
- requires a network load balancer (service VPC) and ENI (customer VPC)
- customer VPC => ENI => private link => NLB => service VPC
- if the NLB is in multiple AZ, and the ENI in multiple AZ, the solution is fault tolerant
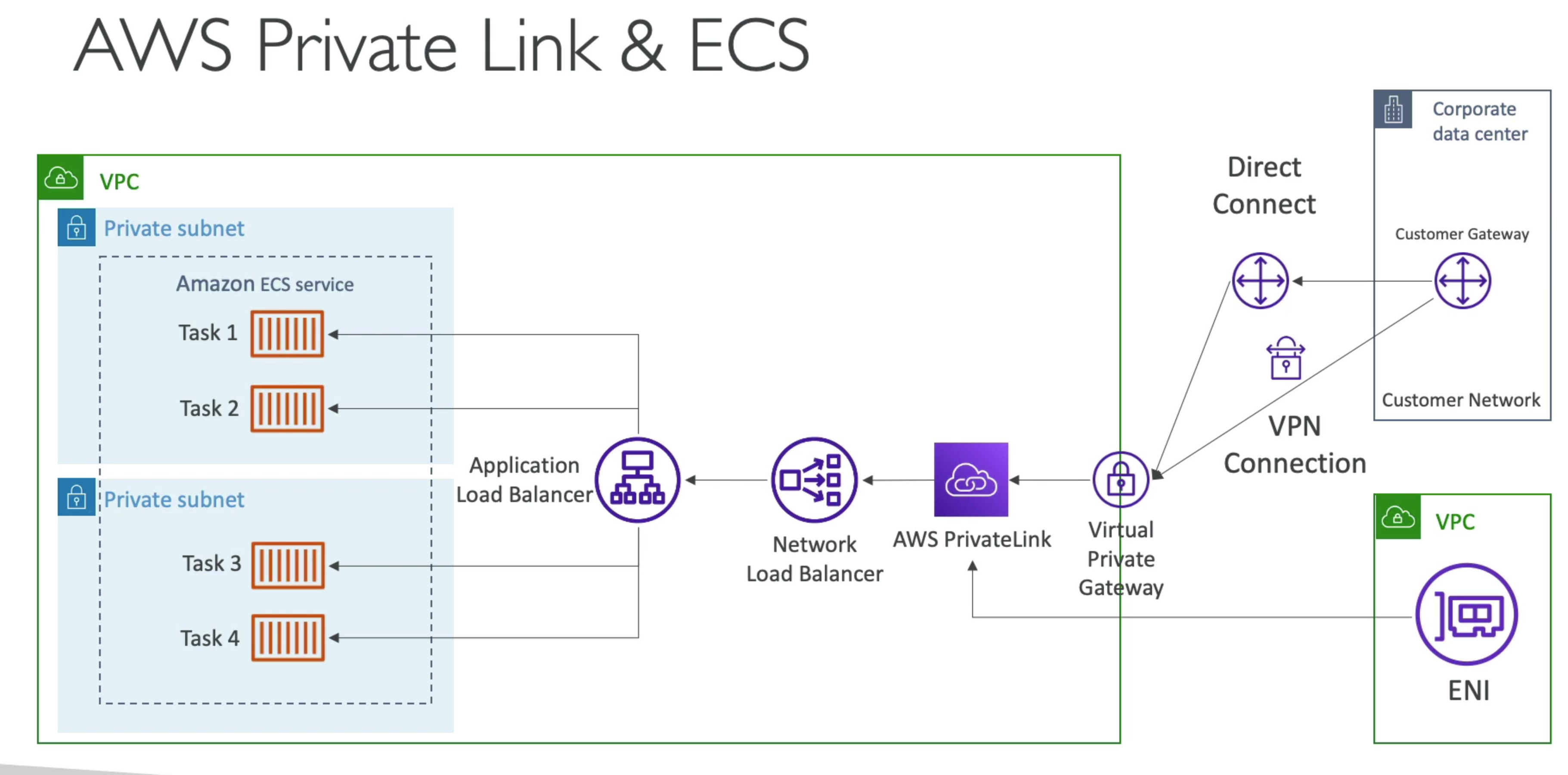
EC2 Classic and AWS ClassicLink (deprecated)
- EC2 classic: instances run in a single network shared with other customers
- Amazon VPC: your instances run logically isolated to your AWS account
- classLink: allows you to link EC2 instances to a VPC in your account
- must associate a security group
- enables communication using private IPv4 addresses
- removes the need to make use of public IPv4 addresses or Elastic IP addresses
- Likely to be distractors at the exam
AWS VPN Cloudhub
- provide secure communication between sites, if you have multiple VPN connections
- low cost hub-and-spoke model for primary or secondary network connectivity between locations
- it is a VPN connection so it goes over the public internet
Transit Gateway
- for having transitive peering between thousands of VPCs and on premises, hub-and-spoke(star) connection
- regional resource, can work cross-region
- share cross account using Resource Access Manager (RAM)
- you can peer transit gateway across regions
- route tables: limit which VPC can talk with other VPC
- works with direct connect gateway, VPN connections
- supports IP multicast (not supported by any other AWS service)
- share direct connect between multiple accounts
- VPCs => transite gateway -> direct connect gateway => AWS direct connect endpoint => customer router
Transit Gateway: site-to-site VPC ECMP
- ECMP = equal cost multi path routing
- routing strategy to allow to forward a packet over multiple best path
- use case: create multiple site-to-site VPN connections to increase the bandwidth of your connection to AWS
VPC Summary
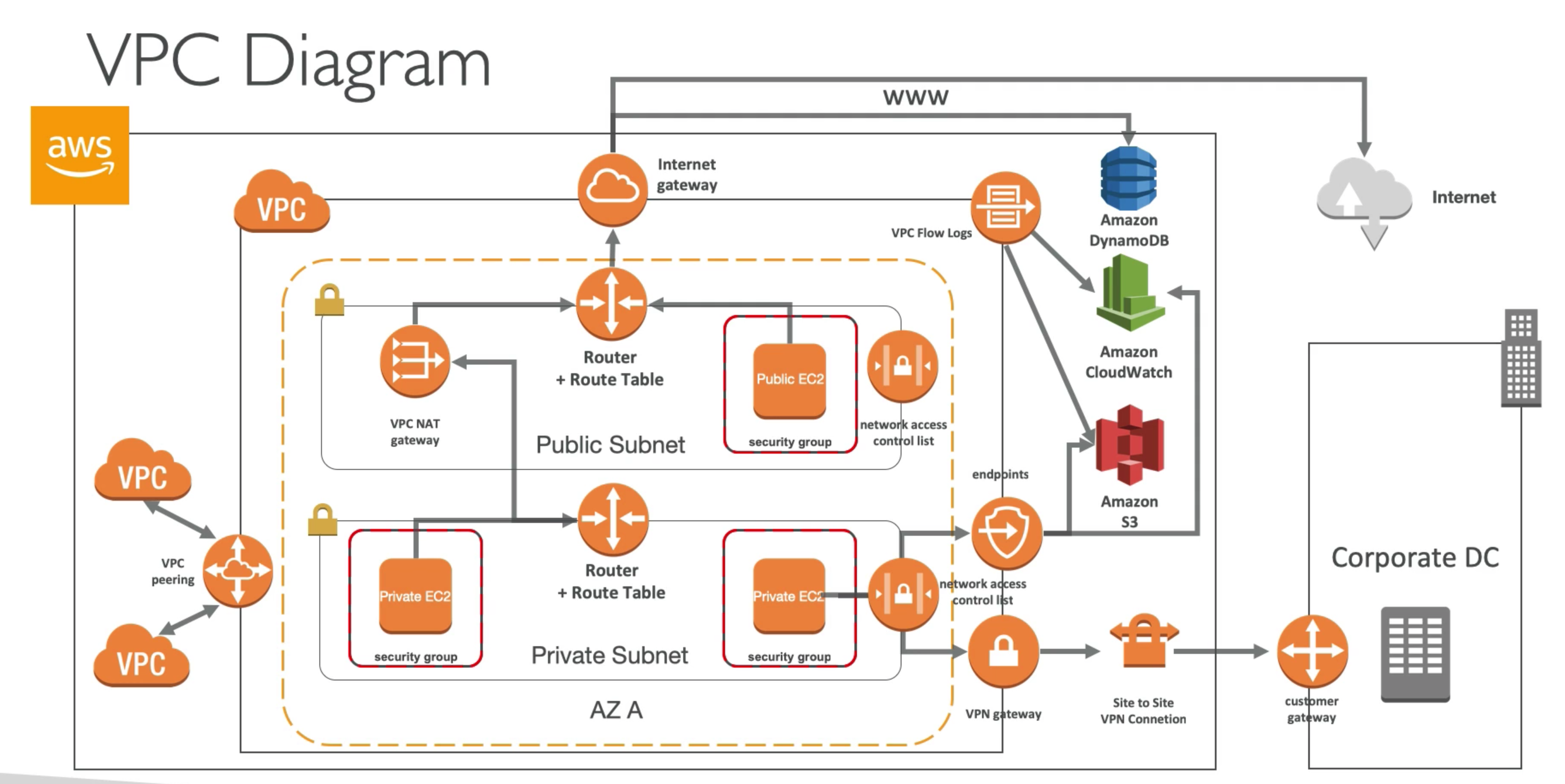
- CIDR: IP range
- VPC: Virtual Private Cloud => we define a list of IPv4 or IPv6 CIDR
- Subnets: Tied to an AZ, we define a CIDR for a subnet
- Internet gateway: at the VPC level, provide internet access
- Route table: must be edited to add routes from subnets to the IGW, VPC peering connections, VPC endpoints, etc…
- NAT Instances: gives internet access to the instances in private subsnets, old, must be setup in a public subnet, disable source / destination check flag
- NAT gateway: managed by AWS, provides scalable internet access to private instances, IPv4 only
- Private DNS + route 53: enable DNS resolution + DNS hostnames (VPC)
- NACL: stateless, subnet rules for inbound and outbound, don’t forget ephemeral ports
- Security groups: stateful, operate at the EC2 instance level
- VPC Peering: connect two VPC with non overlapping CIDR, non transitive
- VPC endpoints: provide private access to AWS services (S3, DynamoDB, CloudFormation, SSM) within VPC, no need to go through internet gateway
- Bastion Host: public instance to SSH into, that has SSH connectivity to instances in private subnets
- Site to Site VPN: setup a customer gateway on Data center, a Virtual Private Gateway on VPC, and site to site VPN over public internet
- Direct Connect: setup a virtual private gateway on VPC, and establish a direct private connection to an AWS direct connection location
- Direct Connect Gateway: setup a direct connect to many VPC in different regions
- internet gateway Egress: like a NAT gateway, but for IPv6
- Private Link / VPC endpoint services
- connect services privately from your service VPC to customers VPC
- doesn’t need VPC peering, public internet, NAT gateway, route tables
- must be used with network load balancer and ENI
- ClassicLInk: connect EC2 classic instances privately to your VPC
- VPC Cloudhub: hun and spoke VPN model to connect your sites
- Transit gateway: transitive peering connections for VPC, VPN and DX
Networking cost in AWS
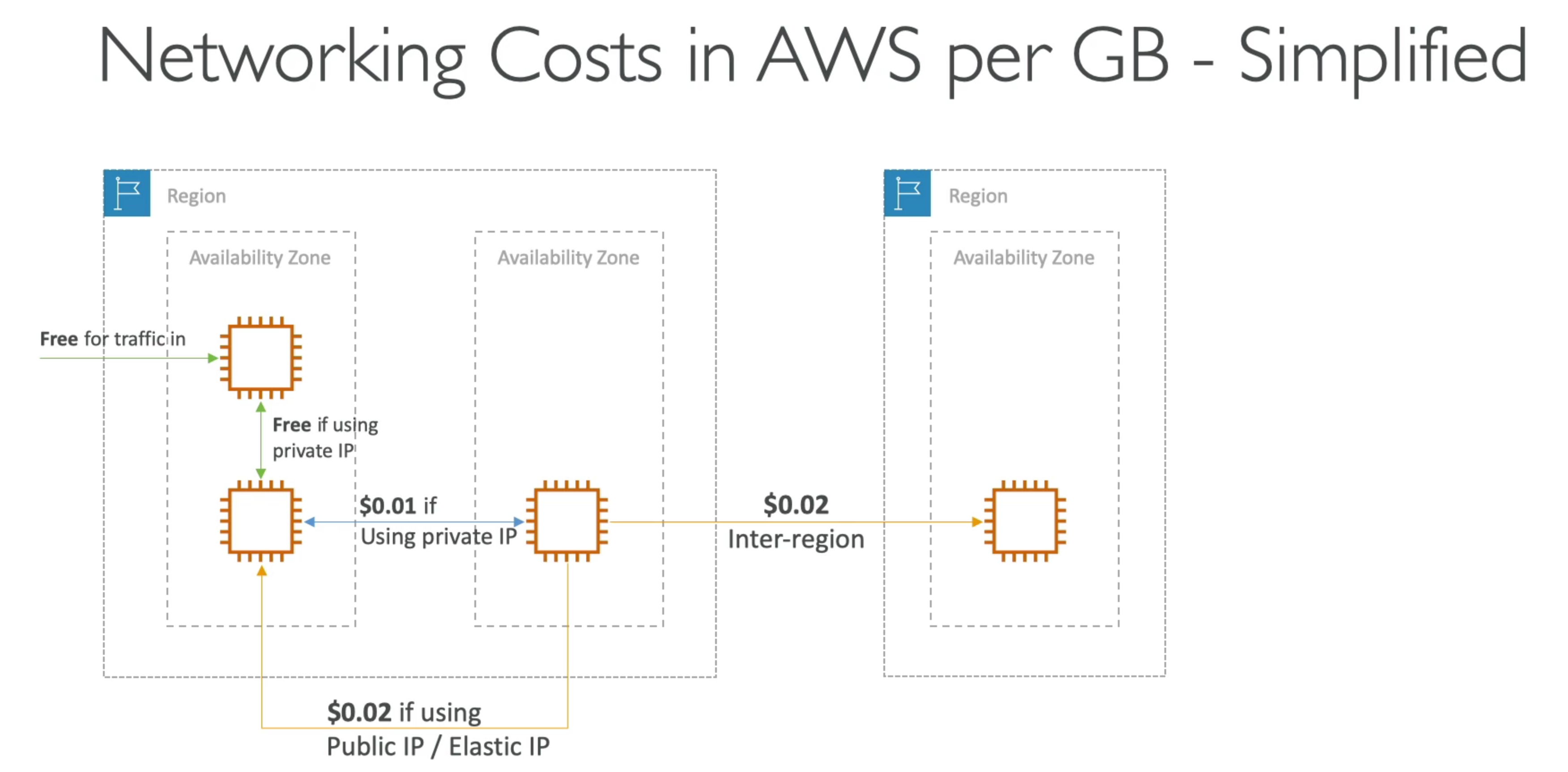
- use private IP instead of public IP for good savings and better network performance
- use same AZ for maximum savings (at the cost of HA)
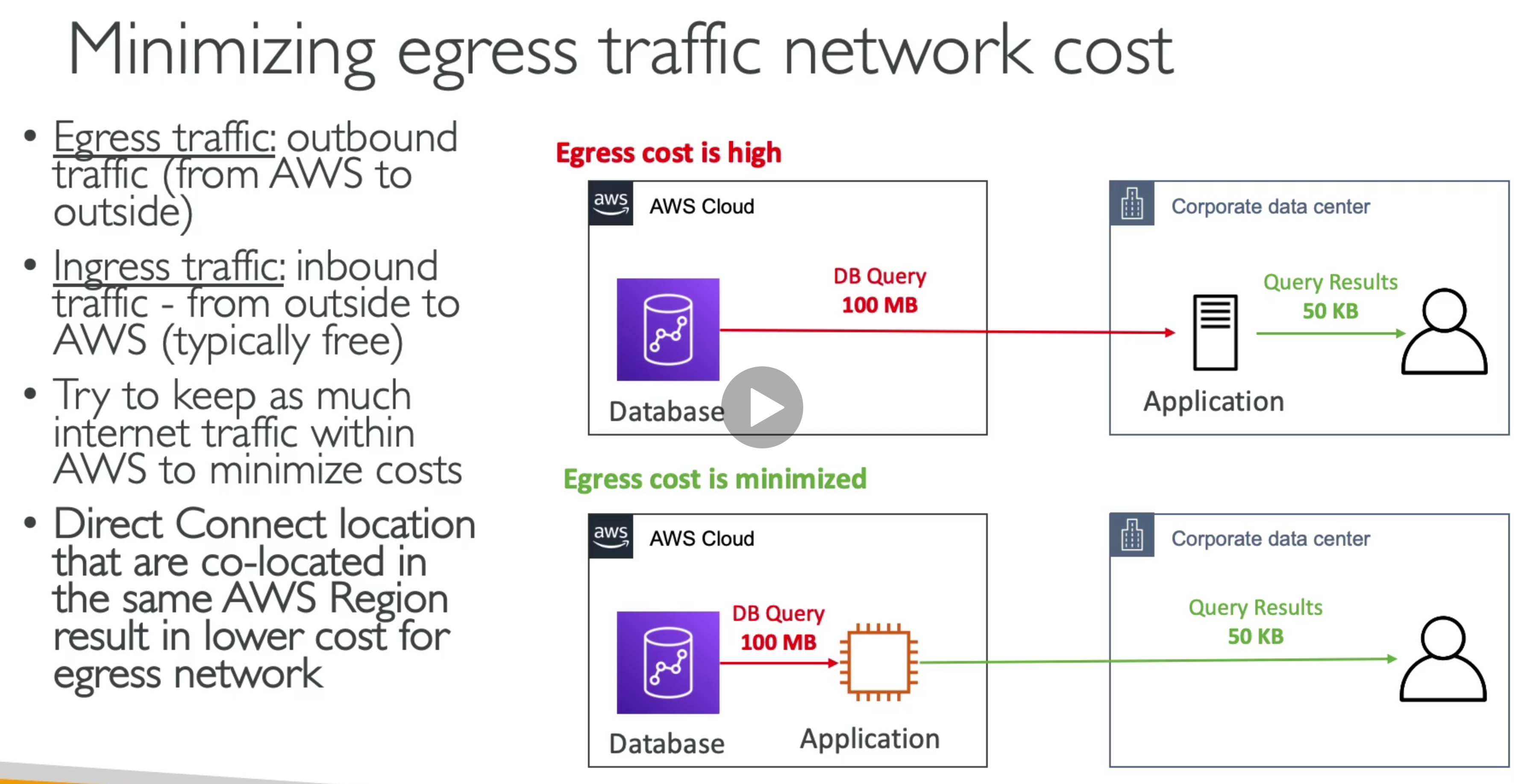
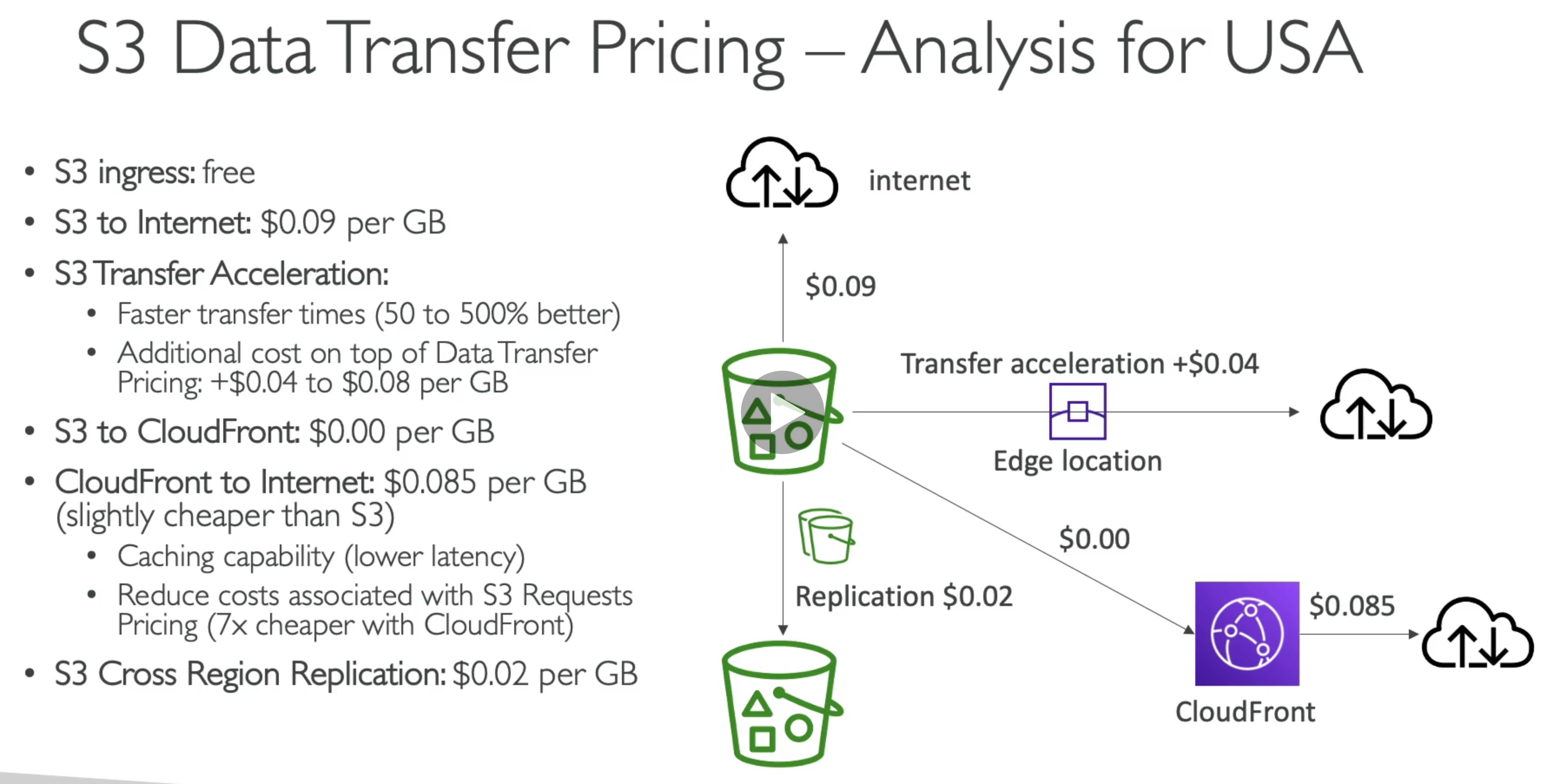
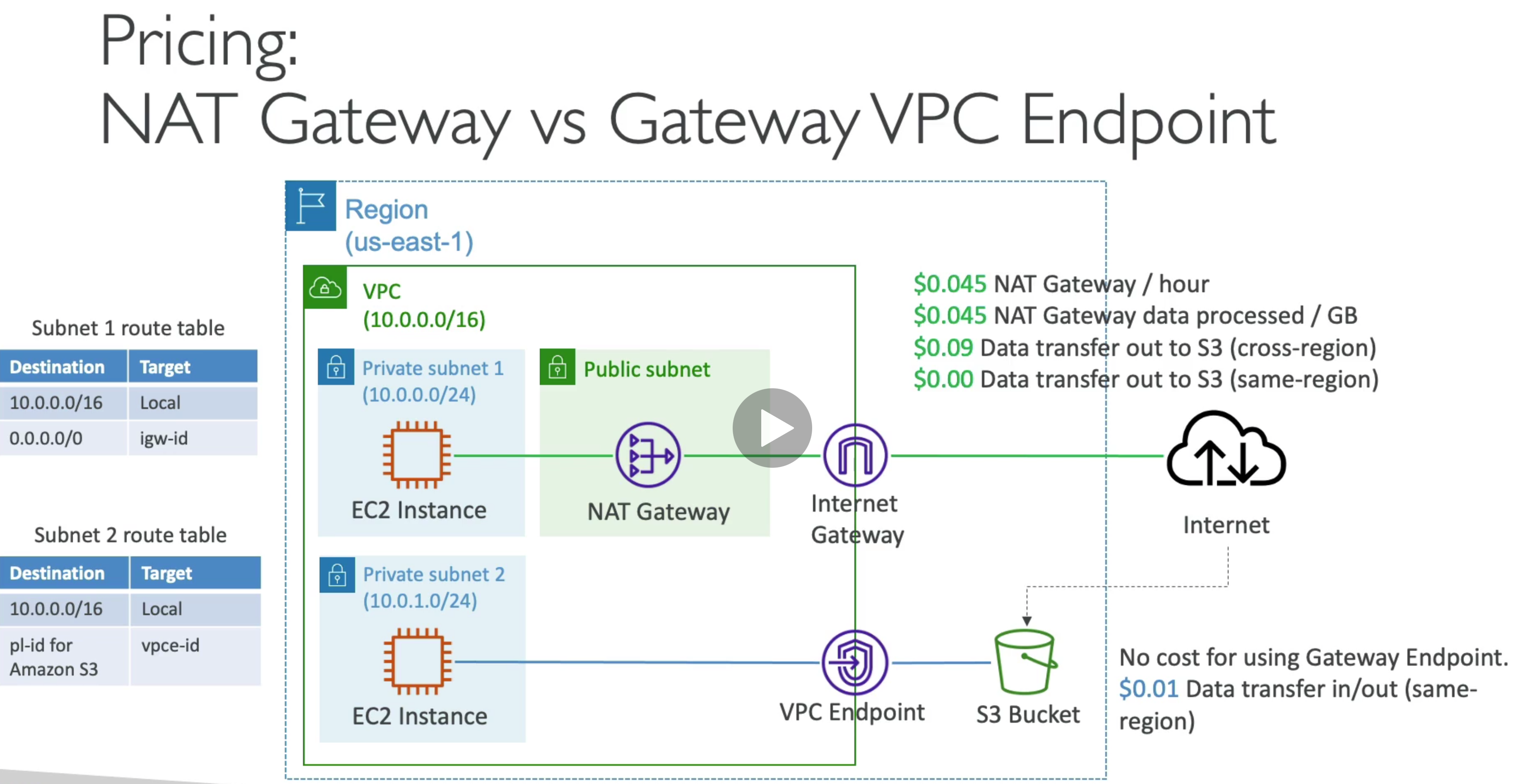
IPv6 for VPC
- IPv4 cannot be disabled for your VPC and subnets
- you can enable IPv6 to operate in dual-stack mode
- your EC2 instance would get at least a private internal IPv4 and a public IPv6
- they can communicate using either IPv4 or IPv6
IPv6 Troubleshooting
- if you cannot launch an instance in your subnet
- it is not because it cannot acquire an IPv6 (the space is very large)
- it is because there are no available IPv4 in your subnet
- solution: create a new IPv4 CIDR in your subnet
Disaster Recovery Overview
- any event that has a negative impact on a company’s business continuity or finances is a disaster
- disaster recovery is about preparing for and recovering from a disaster
- what kind of disaster recovery
- on premises => on premises: tranditional DR, very expensive
- on premises => AWS Cloud: hybrid recovery
- AWS Cloud Region A => AWS Cloud Region B
- need to define 2 terms
- RPO: recovery point objective
- RTO: recovery time objective
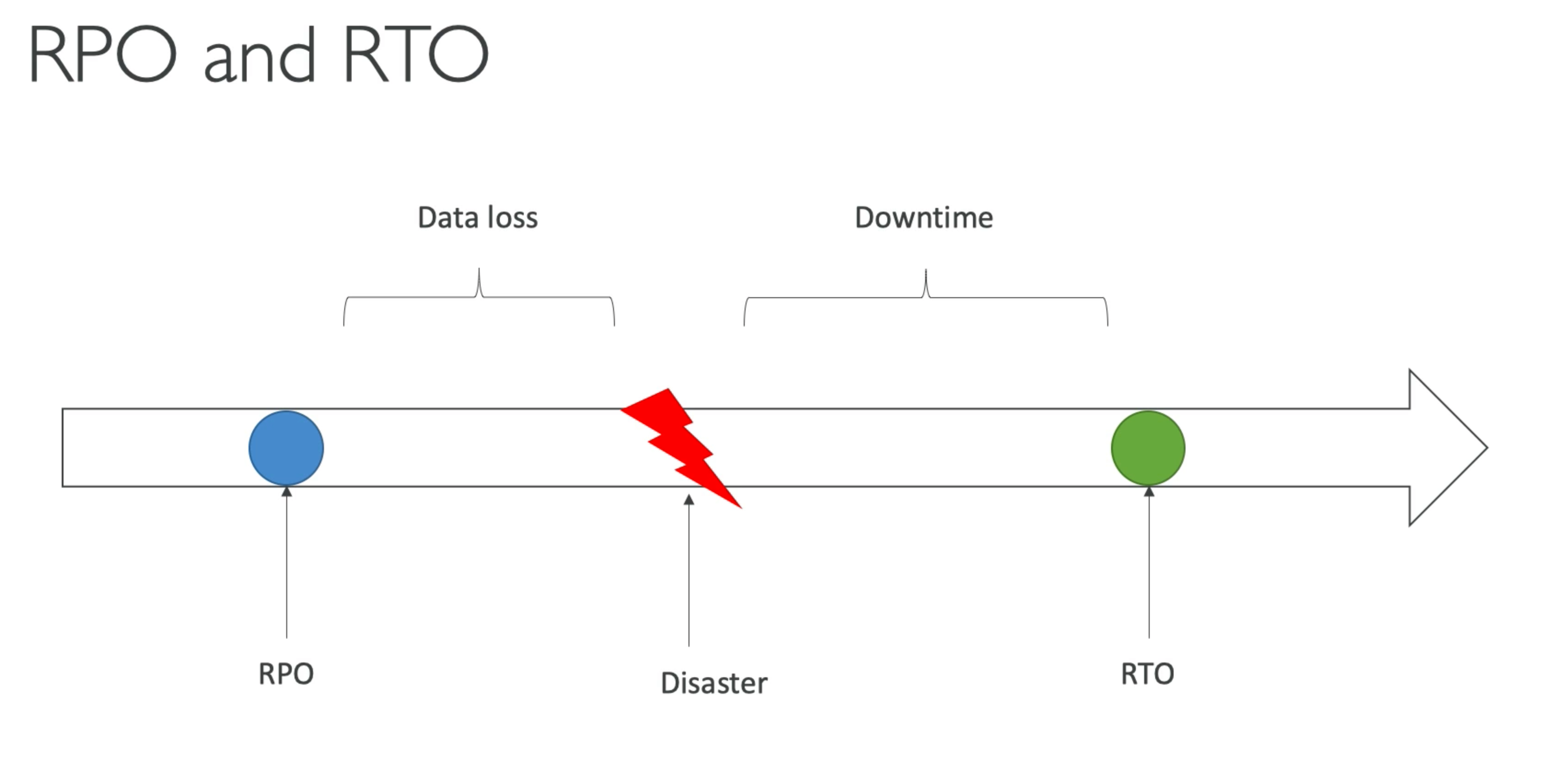
Backup and restore (High RPO)
- needs more time to recover
Pilot Light
- a small version of the app is always running in the cloud
- useful for the critical core (pilot light)
- very similar to backup and restore
- faster than backup and restore as critical systems are already up
Warm Standby
- full system is up and running but at minimum size
- upon disaster, we can scale up to production load
Multi Site / Hot Site Approach
- very low RTO (minutes or seconds) - very expensive
- full production scale is running AWS and on premises
Disaster Recovery Tips
- backup
- EBS snapshots, RDS automated backups / snapshots, etc…
- regular pushes to S3 / S3 IA / Glacier, Lifecycle policy, cross region replication
- from on premises: snowball or storage gateway
- HA
- use route 53 to migrate DNS over from region to region
- RDS multi AZ, elastiCache multi AZ, EFS, S3
- site to site VPN as a recovery from direct connect
- replication
- RDS replication, AWS Aurora + global databases
- database replication from on premises to RDS
- storage gateway
- automation
- cloudFormation / elastic beanstalk to re-create a whole new environment
- recover / reboot EC2 instance with cloudwatch if alarms fails
- AWS lambda functions for customized automations
- chans
- Netflix has a simian-army randomly terminating EC2
DMS - Database Migration Service
- quickly and securely migrate databases to AWS, resilient, self healing
- the source database remains available during the migration
- supports
- homogeneous migrations: Oracle to Oracle
- Heterogeneous: Microsoft SQL server to Aurora
- continuous Data replication using CDC
- you must create an EC2 instance to perform the replication tasks
AWS Schema Conversion Tool (SCT)
- convert your database’s schema from one engine to another
- example OLTP: sql server or Oracle => MySQL, PostgreSQL, Aurora
- example OLAP: Teradata or Oracle => Amazon Redshift
- you do not need to use SCT if you are migrating the same DB engine
- on premise postgreSQL => RDS postgreSQL
- the DB engine is still PostgreSQL (RDS is just a platform)
On Premises Strategy with AWS
- ability to download Amazon Linux 2 AMI as a VM
- use VMWare, KVM, VirtualBox to run VM
- VM import / Export
- migrate existing applications into EC2
- create a DR repository strategy for your on premises VMs
- can export abck the VMs from EC2 to on premises
- AWS application discovery services
- gather information about your on premises server to plan a migration
- server utilization and dependency mappings
- track with AWS migration hub
- AWS database migration server (DMS)
- replicate on premise => AWS
- AWS => AWS
- AWS => on premises
- AWS server migration service (SMS)
- incremental replication of on premises live servers to AWS
AWS DataSync
- move large amount of data from on premise to AWS
- can synchronize to: Amazon S3 (any storage class, including Glacier), Amazon EFS, FSx for Windows
- move data from your NAS or file system via NFS or SMB
- replication tasks can be scheduled hourly, daily or weekly
- leverage the DataSync agent to connect to your systems
- can setup a bandwidth limit
AWS Backup
- fully managed service
- centrally manage and automate backups across AWS services
- no need to create custom scripts and manual processes
- supported services
- FSx
- EFS
- DynamoDB
- EC2
- EBS
- RDS
- Aurora
- AWS storage gateway (volume gateway)
- supports cross region backups
- supports cross account backups
- supports PITR (point in time recovery) for supported services
- on demand and scheduled backups
- tag based backup policies
- you create backup policies known as Backup Plans
- backup frequency
- backup window
- transition to cold storage
- retention period
More Solution Architectures
Compute and Networking
- EC2 enhanced networking (SR-IOV)
- higher bandwidth, higher PPS (packet per second), lower latency
- option1: Elastic Network Adapter (ENA) up to 100 Gbps
- option2: Intel, up to 10 Gbps, legacy
- Elastic Fabric Adapter (EFA)
- improved ENA for HPC, only works for Linux
- great for inter node communications, tightly coupled networks
- leverages message passing interface (MPI) standard
- bypasses the underlying linux OS to provide low latency, reliable transport
CloudFormation
- a declarative way of outlining your AWS infrastructure, for any resources
- for example, within a CloudFormation template, you say
- I want a security group
- 2 EC2 instances using this security group
- 2 Elastic IPs for these EC2 machines
- 1 S3 bucket
- a load balancer in front of these machines
- then cloudformation creates those for you, in the right order, with the exact configuration that you specify
- templates have to be uploaded in S3 and then referenced in CloudFormation
- to update a template, we can’t edit previous ones, we have to re-upload a new version of the template to AWS
- stacks are identified by a name
- deleting a stack deletes every single artifact that was created by CloudFormation
Deploying CloudFormation templates
- manual way
- editing templates in the CloudFormation designer
- using the console to input parameters, etc…
- automated way
- editing templates in a YAML file
- using the AWS CLI to deploy the templates
- recommended way when you fully want to automate your flow
CloudFormation - stacksets
- create, update, or delete stacks across multiple accounts and regions with a single operation
- administrator account to create stacksets
- trusted accounts to create, update, delete stack instances from stacksets
- when you update a stackset, all associated stack instances are updated throughout all accounts and regions
AWS Step Functions
- build serverless visual workflow to orchestrate your lambda functions
- represent flow as a JSON state machine
- features: sequence, parallel, conditions, timeouts, error handling
- can also integrate with EC2, ECS, on premise servers, API gateway
- possiblity to implement human approval feature
AWS SWF - simple workflow service
- coordinate work amongst applications
- code runs on EC2
- concept of activity step and decision step
- has built in human intervention step
- step function is recommended to be used for new applications, except
- if you need external signals to intervene in the processes
- if you need child processes that return values to parent processes
Amazon EMR
- EMR stands for Elastic Map Reduce
- EMR helps creating Hadoop clusters (big data) to analyze and process vast amount of data
- the clusters can be made of hundreds of EC2 instances
- also supports Apache Spark, HBase, Presto, Flink
- EMR takes care of all the provisioning and configuration
- auto scaling and integrated with Spot instances
- use cases: data processing, machine learning, web indexing, big data
AWS Opsworks
-
Chef and Puppet help you perform server configuration automatically, or repetitive actions
-
they work great with EC2 and on premises VM
-
AWS Opsworks = managed Chef and Puppet
-
it is an alternative to AWS SSM
-
they help with managing configuration as code
-
helps in having consistent deployments
-
works with Linux and Windows
AWS Elastic Transcoder
- convert media files (video + music) stored in S3 into various formats for tablets, PC, smartphone, TV etc…
- features: bit rate optimization, thumbnail, watermarks, captions, DRM, progressive download, encryption
- 4 components
- jobs: what does the work of the transcoder
- pipeline: queue that manages the transcoding job
- presets: template for converting media from one format to another
- notifications: SNS for exmaple
- pay for what you use, scales automatically, fully managed
AWS WorkSpaces
- managed, secure cloud desktop
- great to eliminate management of on premise VDI (virtual desktop infrastructure)
- on demand, pay per by usage
- secure, encrypted, network isolation
- integrated with Microsoft active directory
AWS AppSync
- store and sync data across mobile and web apps in real time
- makes use of GraphQL (mobile technology from Facebook)
- client code can be generated automatically
- integrations with DynamoDB
- real time subscriptions
Cost Explorer
- visualize, understand and manage your AWS costs and usage over time
- create custom reports that analyze cost and usage data
- analyze your data at a high level, total costs and usage across all accounts
- choose an optimal savings plan
- forecast usage up to 12 months based on previous usage
CheatSheet
-
CodeCommit: service where you can store your code. Similar service is GitHub
-
CodeBuild: build and testing service in your CICD pipelines
-
CodeDeploy: deploy the packaged code onto EC2 and AWS Lambda
-
CodePipeline: orchestrate the actions of your CICD pipelines (build stages, manual approvals, many deploys, etc)
-
CloudFormation: Infrastructure as Code for AWS. Declarative way to manage, create and update resources.
-
ECS (Elastic Container Service): Docker container management system on AWS. Helps with creating micro-services.
-
ECR (Elastic Container Registry): Docker images repository on AWS. Docker Images can be pushed and pulled from there
-
Step Functions: Orchestrate / Coordinate Lambda functions and ECS containers into a workflow
-
SWF (Simple Workflow Service): Old way of orchestrating a big workflow.
-
EMR (Elastic Map Reduce): Big Data / Hadoop / Spark clusters on AWS, deployed on EC2 for you
-
Glue: ETL (Extract Transform Load) service on AWS
-
OpsWorks: managed Chef & Puppet on AWS
-
ElasticTranscoder: managed media (video, music) converter service into various optimized formats
-
Organizations: hierarchy and centralized management of multiple AWS accounts
-
Workspaces: Virtual Desktop on Demand in the Cloud. Replaces traditional on-premise VDI infrastructure
-
AppSync: GraphQL as a service on AWS
-
SSO (Single Sign On): One login managed by AWS to log in to various business SAML 2.0-compatible applications (office 365 etc)

